Mục lục [Ẩn]
Trong thời đại mà dữ liệu được ví như “nhiên liệu của kỷ nguyên số”, việc thu thập dữ liệu tự động không còn là lựa chọn, mà đã trở thành yếu tố sống còn giúp doanh nghiệp tăng tốc và ra quyết định chính xác hơn. Thay vì nhập liệu thủ công, các hệ thống tự động ứng dụng AI giúp doanh nghiệp thu thập, xử lý và phân tích dữ liệu theo thời gian thực. Cùng AI First tìm hiểu giải pháp tự động hóa thu thập dữ liệu, giúp SME tiết kiệm chi phí, tối ưu quy trình và nâng cao năng lực ra quyết định trong mọi lĩnh vực.
Các ý chính trong bài viết:
- Giải thích thu thập dữ liệu tự động là gì.
- Vấn đề phổ biến của doanh nghiệp khi thu thập dữ liệu thủ công.
- Các loại dữ liệu có thể tự động thu thập: Dữ liệu khách hàng, dữ liệu hành vi người dùng, dữ liệu marketing, dữ liệu bán hàng, dữ liệu thị trường, dữ liệu tài chính.
- Các hình thức và phương pháp thu thập dữ liệu tự động.
- Quy trình triển khi thu thập dữ liệu tự động: Từ xác định mục tiêu, phát hiện cấu trúc, thiết kế bot, xử lý và làm sạch dữ liệu đến lưu trữ dữ liệu.
- Thách thức khi thu thập dữ liệu tự động.
1. Thu thập dữ liệu tự động là gì?
Thu thập dữ liệu tự động là quá trình sử dụng phần mềm, bot hoặc công nghệ để tự động lấy thông tin từ nhiều nguồn như website, API, mạng xã hội, hệ thống nội bộ hoặc thiết bị IoT mà không cần thao tác thủ công. Phương pháp này giúp doanh nghiệp tiết kiệm thời gian, giảm sai sót và dễ dàng mở rộng quy mô xử lý dữ liệu.

Dữ liệu thu thập có thể là thông tin khách hàng, giá sản phẩm, phản hồi người dùng, hoặc nội dung từ đối thủ. Đây là bước nền tảng để áp dụng phân tích dữ liệu, tự động hóa và trí tuệ nhân tạo (AI) vào vận hành doanh nghiệp.
2. Vấn đề phổ biến của doanh nghiệp khi thu thập dữ liệu thủ công
Trong quá trình vận hành, rất nhiều doanh nghiệp SME vẫn đang thu thập dữ liệu theo phương pháp thủ công. Mặc dù dễ triển khai ở giai đoạn đầu, nhưng cách làm này tiềm ẩn nhiều rủi ro và bất cập nếu doanh nghiệp muốn mở rộng quy mô, tăng tốc ra quyết định hay chuyển đổi số toàn diện.

1 - Dễ xảy ra sai sót và dữ liệu thiếu nhất quán
Khi dữ liệu được nhập thủ công, con người luôn là “mắt xích yếu” trong chuỗi quản lý thông tin. Một lỗi nhỏ trong nhập liệu có thể dẫn đến sai sót lớn trong phân tích, đặc biệt với các doanh nghiệp có lượng dữ liệu lớn từ bán hàng, marketing, hay tài chính. Sai số này không chỉ làm sai lệch báo cáo mà còn ảnh hưởng trực tiếp đến chiến lược vận hành, định giá, và hoạch định kinh doanh của doanh nghiệp.
- Nhập liệu thủ công dễ sai lệch: Khi nhân viên nhập dữ liệu bằng tay, chỉ cần một lỗi nhỏ như sai số hoặc nhầm mã khách hàng có thể làm sai toàn bộ kết quả phân tích.
- Thiếu quy chuẩn kiểm tra dữ liệu: Không có hệ thống xác thực tự động, dữ liệu thường bị trùng lặp hoặc thiếu sót, gây khó khăn cho việc tổng hợp.
- Ảnh hưởng đến ra quyết định: Số liệu sai lệch dẫn đến phân tích sai, ảnh hưởng đến hiệu quả chiến dịch marketing, tài chính hay vận hành.
2 - Tốn nhiều thời gian và chi phí nhân sự
Thu thập dữ liệu thủ công là công việc đòi hỏi sự lặp lại liên tục, gây hao tổn đáng kể về thời gian và chi phí nhân lực. Doanh nghiệp phải dành hàng giờ mỗi ngày chỉ để tổng hợp, đối soát hoặc nhập dữ liệu. Việc này khiến nhân sự không còn đủ thời gian để tập trung vào các hoạt động chiến lược có giá trị cao hơn như phân tích, sáng tạo hoặc ra quyết định.
- Mất hàng giờ để nhập và tổng hợp dữ liệu: Các bộ phận phải tốn nhiều thời gian cho các thao tác lặp lại như nhập thông tin khách hàng, doanh số, hoặc báo cáo bán hàng.
- Chi phí nhân sự cao: Doanh nghiệp phải duy trì đội ngũ nhập liệu lớn, trong khi công việc này hoàn toàn có thể được tự động hóa bằng AI hoặc phần mềm.
- Giảm năng suất tổng thể: Thay vì tập trung vào các hoạt động mang lại giá trị như phân tích dữ liệu hay hoạch định chiến lược, nhân sự bị kẹt trong công việc hành chính.
3 - Dữ liệu bị phân mảnh, khó quản lý tổng thể
Một trong những vấn đề nghiêm trọng nhất khi doanh nghiệp thu thập dữ liệu thủ công là thiếu tính tập trung. Dữ liệu thường được lưu rải rác ở nhiều phòng ban, nhiều file khác nhau, thậm chí mỗi nhân viên lại có cách lưu trữ riêng. Kết quả là doanh nghiệp không có cái nhìn tổng thể về khách hàng, doanh số hay hiệu quả vận hành, dẫn đến ra quyết định chậm và thiếu chính xác.
- Không có nguồn dữ liệu tập trung: Dữ liệu được lưu trữ ở nhiều nơi khác nhau như file Excel, Google Sheet, phần mềm CRM, khiến việc đối soát trở nên phức tạp.
- Khó truy xuất thông tin: Khi cần báo cáo nhanh, doanh nghiệp mất nhiều thời gian để tổng hợp và xác minh lại số liệu.
- Cản trở chuyển đổi số: Thiếu sự đồng bộ dữ liệu khiến việc triển khai các hệ thống AI, hệ thống ERP hay CRM gặp khó khăn.
4 - Thiếu khả năng phân tích và dự đoán
Việc thu thập dữ liệu thủ công khiến doanh nghiệp gần như không thể khai thác giá trị thật sự từ dữ liệu. Thay vì phân tích xu hướng, dự đoán hành vi khách hàng hay đo lường hiệu quả chiến dịch, phần lớn thời gian lại bị tiêu tốn cho việc làm sạch, chuẩn hóa và tổng hợp số liệu. Điều này khiến doanh nghiệp bỏ lỡ cơ hội tối ưu chiến lược dựa trên dữ liệu (data-driven decision-making).
5 - Rủi ro bảo mật và mất mát dữ liệu
Bảo mật là yếu tố sống còn của mọi doanh nghiệp, nhưng khi dữ liệu được quản lý thủ công, rủi ro mất mát hoặc rò rỉ là điều khó tránh khỏi. Việc lưu trữ dữ liệu trong file Excel, USB, hoặc gửi qua email nội bộ khiến doanh nghiệp dễ dàng bị mất dữ liệu khi có sự cố kỹ thuật hoặc thay đổi nhân sự.
- Dễ thất lạc hoặc rò rỉ thông tin: Lưu trữ dữ liệu trong file hoặc email nội bộ làm tăng nguy cơ mất mát, đặc biệt khi có nhân viên nghỉ việc hoặc thay đổi thiết bị.
- Không có cơ chế sao lưu an toàn: Nếu không dùng hệ thống cloud hoặc phần mềm quản trị dữ liệu, doanh nghiệp có thể mất toàn bộ dữ liệu khi gặp sự cố.
- Thiếu quyền kiểm soát truy cập: Bất kỳ ai trong tổ chức cũng có thể truy cập hoặc chỉnh sửa dữ liệu, dẫn đến nguy cơ sai lệch và mất kiểm soát thông tin.
3. Các loại dữ liệu có thể tự động thu thập
Trong kỷ nguyên số, dữ liệu chính là tài sản chiến lược của doanh nghiệp. Nhờ ứng dụng công nghệ và trí tuệ nhân tạo (AI), giờ đây việc thu thập dữ liệu tự động trở nên dễ dàng hơn bao giờ hết. Dưới đây là những loại dữ liệu doanh nghiệp có thể tự động thu thập.

Các loại dữ liệu có thể tự động thu thập:
- Dữ liệu khách hàng: Giúp doanh nghiệp hiểu khách hàng là ai, họ cần gì và hành vi của họ ra sao.
- Dữ liệu hành vi người dùng: Phản ánh cách khách hàng tương tác với sản phẩm, website hay quảng cáo.
- Dữ liệu marketing & chiến dịch quảng cáo: Thu thập tự động dữ liệu từ các nền tảng quảng cáo như Google Ads, Facebook, TikTok để đo lường hiệu quả chiến dịch, chi phí/lead, ROI và hành trình khách hàng.
- Dữ liệu bán hàng & vận hành: Bao gồm dữ liệu về doanh thu, đơn hàng, tồn kho, vận chuyển, hiệu suất nhân viên, được cập nhật theo thời gian thực.
- Dữ liệu thị trường & đối thủ: AI có thể tự động quét hàng nghìn nguồn công khai để thu thập thông tin về giá, xu hướng thị trường, phản hồi người tiêu dùng và hoạt động của đối thủ.
3.1. Dữ liệu khách hàng
Dữ liệu khách hàng là nền tảng của mọi chiến lược tăng trưởng. Thay vì thu thập thông tin rời rạc qua form, hội thoại hay Excel, doanh nghiệp có thể dùng các công cụ AI để tự động ghi nhận toàn bộ hành vi, thông tin và lịch sử tương tác của từng khách hàng theo thời gian thực. Việc thu thập tự động này giúp doanh nghiệp xây dựng bức chân dung 360 độ về khách hàng phục vụ hiệu quả cho cá nhân hóa trải nghiệm và giữ chân khách hàng trung thành.
- Thông tin định danh cá nhân: Bao gồm họ tên, tuổi, giới tính, địa điểm sinh sống, thiết bị sử dụng. AI có thể tự động nhận diện và ghi nhận từ các form đăng ký, tài khoản mạng xã hội hoặc hành vi truy cập web.
- Hành vi truy cập và tương tác: Theo dõi hành trình của người dùng từ lúc vào website, đọc bài viết, xem sản phẩm đến khi thực hiện hành động như đăng ký, đặt hàng hoặc thoát trang.
- Dữ liệu cảm xúc và phản hồi: AI có thể phân tích nội dung bình luận, tin nhắn hoặc đánh giá để xác định cảm xúc (tích cực/tiêu cực) và mức độ hài lòng của khách hàng.
- Lịch sử giao dịch và hành vi mua hàng: Hệ thống CRM có thể tự động ghi lại tần suất mua, giá trị trung bình mỗi đơn hàng, sản phẩm ưa thích và thời điểm mua cao nhất.
- Kênh tương tác ưa thích: AI phân tích để biết khách hàng thích liên hệ qua kênh nào (Facebook, Zalo, Email hay Website), giúp doanh nghiệp tối ưu cách chăm sóc.
3.2. Dữ liệu hành vi người dùng
Đây là nhóm dữ liệu phản ánh hành vi thực tế của người dùng khi họ tương tác với doanh nghiệp trên các nền tảng kỹ thuật số. Nếu dữ liệu khách hàng cho biết “họ là ai”, thì dữ liệu hành vi cho biết “họ làm gì, và tại sao họ làm vậy”. Hệ thống thu thập tự động giúp ghi nhận mọi tương tác nhỏ từ lượt cuộn chuột, click vào nút CTA, cho đến tần suất truy cập để doanh nghiệp hiểu sâu hơn về động cơ, thói quen và ý định mua hàng.

- Dữ liệu duyệt web: Ghi lại toàn bộ hành trình người dùng: họ vào từ đâu, ở lại trang nào lâu nhất, nội dung nào khiến họ rời đi. Công cụ như Google Analytics 4 hoặc AI tracking giúp doanh nghiệp phát hiện insight hành vi tiềm ẩn.
- Tương tác trong ứng dụng: Với doanh nghiệp có app, AI có thể phân tích hành vi sử dụng tính năng, thời gian phiên, hoặc sự kiện người dùng thực hiện nhiều nhất để tối ưu trải nghiệm.
- Dữ liệu tương tác trên quảng cáo: Theo dõi tỷ lệ nhấp (CTR), tỷ lệ chuyển đổi (CVR), thời gian xem video quảng cáo, giúp doanh nghiệp xác định đâu là thông điệp thu hút nhất.
- Hành vi lặp lại: AI nhận diện các mẫu hành vi lặp lại như truy cập theo ngày, tìm kiếm sản phẩm tương tự hoặc quay lại mua hàng theo chu kỳ.
3.3. Dữ liệu marketing và chiến dịch quảng cáo
Trong bối cảnh cạnh tranh cao, doanh nghiệp cần biết mỗi đồng chi tiêu marketing mang lại hiệu quả gì. Việc thu thập dữ liệu quảng cáo tự động từ nhiều kênh giúp marketer không còn phải tổng hợp thủ công từ Google, Facebook, TikTok, mà có thể theo dõi hiệu quả chiến dịch trên một dashboard duy nhất.
- Dữ liệu hiệu suất chiến dịch: Bao gồm số lần hiển thị, click, tỷ lệ chuyển đổi, chi phí/lead và chi phí/doanh thu (ROAS). Hệ thống AI có thể tự động kết nối API để lấy dữ liệu từ nhiều nền tảng.
- Dữ liệu hành trình khách hàng (Customer Journey): Theo dõi khách hàng đi qua bao nhiêu điểm chạm trước khi ra quyết định mua hàng, giúp tối ưu kênh và nội dung.
- Phân tích nguồn traffic: AI tự động phân loại traffic theo nguồn (SEO, social, referral, paid media), cho phép đánh giá kênh nào hiệu quả nhất.
- Phân tích cảm xúc và xu hướng nội dung: AI có thể quét nội dung quảng cáo để đo mức độ hấp dẫn và cảm xúc người xem (sentiment analysis).
- Dự đoán hiệu quả chiến dịch: Bằng mô hình học máy (machine learning), doanh nghiệp có thể dự đoán ROI và tối ưu ngân sách trước khi chiến dịch chạy.
3.4. Dữ liệu bán hàng và vận hành
Dữ liệu bán hàng và vận hành phản ánh “mạch sống” của doanh nghiệp. Khi được thu thập tự động, các con số như doanh thu, tồn kho, quy trình giao hàng, năng suất nhân viên sẽ luôn được cập nhật chính xác, giúp lãnh đạo có thể ra quyết định tức thì, thay vì phải chờ đợi báo cáo hàng tuần hoặc hàng tháng.

- Doanh thu và đơn hàng: AI có thể tự động tổng hợp doanh thu theo ngày, theo sản phẩm, theo khu vực hoặc theo nhân viên bán hàng.
- Quản lý kho thông minh: Tự động cập nhật tồn kho, cảnh báo khi sản phẩm sắp hết hoặc tồn quá lâu, từ đó tối ưu dòng tiền và tránh lãng phí.
- Dữ liệu vận chuyển: Kết nối API với các đơn vị logistics để theo dõi trạng thái đơn hàng theo thời gian thực, giảm khiếu nại từ khách hàng.
- Hiệu suất nhân viên: Ghi nhận năng suất bán hàng, tốc độ xử lý đơn, thời gian phản hồi khách hàng để tối ưu KPI nội bộ.
- Báo cáo vận hành tự động: AI tổng hợp dữ liệu từ nhiều bộ phận (bán hàng, kho, vận chuyển, kế toán) để tạo dashboard báo cáo theo ngày.
3.5. Dữ liệu thị trường và đối thủ cạnh tranh
Đây là nhóm dữ liệu mang tính chiến lược, giúp doanh nghiệp nắm bắt “chuyển động thị trường” và phản ứng nhanh hơn đối thủ. Thay vì thuê đội nghiên cứu thị trường tốn kém, AI có thể tự động quét hàng trăm nghìn dữ liệu công khai mỗi ngày để cung cấp insight chính xác.
- Dữ liệu giá sản phẩm và khuyến mãi đối thủ: AI có thể theo dõi thay đổi giá trên sàn thương mại điện tử, website hoặc quảng cáo.
- Phân tích xu hướng tìm kiếm (Search Trend): Tự động cập nhật các từ khóa hot trong ngành từ Google Trends, TikTok hoặc YouTube.
- Phản hồi người tiêu dùng: Thu thập review, bình luận và xếp hạng của khách hàng với sản phẩm cùng loại.
- Dữ liệu sản phẩm mới: AI nhận diện khi đối thủ tung sản phẩm mới hoặc thay đổi thông điệp truyền thông.
- Phân tích mức độ cạnh tranh: Đánh giá độ phủ thương hiệu, thị phần và mức độ tương tác của đối thủ.
3.6. Dữ liệu tài chính và kế toán
Dữ liệu tài chính là nhóm thông tin đòi hỏi độ chính xác tuyệt đối, vì chỉ cần sai lệch nhỏ cũng có thể dẫn đến sai quyết toán hoặc tổn thất nghiêm trọng. AI có thể tự động thu thập, kiểm tra và đối chiếu dữ liệu tài chính từ nhiều hệ thống khác nhau giúp đảm bảo tính toàn vẹn, minh bạch và an toàn.
- Dữ liệu giao dịch và hóa đơn: Tự động trích xuất thông tin từ hóa đơn điện tử, biên lai, sao kê ngân hàng bằng công nghệ OCR.
- Dòng tiền và chi phí: AI tự động phân loại chi phí theo loại (marketing, vận hành, nhân sự, sản xuất), giúp doanh nghiệp theo dõi cash flow hàng ngày.
- Công nợ và thanh toán: Hệ thống tự động cảnh báo công nợ sắp đến hạn, tránh tình trạng chậm thanh toán hoặc nợ xấu.
- Báo cáo tài chính tự động: AI tổng hợp dữ liệu từ phần mềm kế toán để tạo báo cáo doanh thu, lợi nhuận, chi phí theo thời gian thực.
4. Các hình thức & phương pháp thu thập dữ liệu tự động
Trong hệ thống dữ liệu hiện đại, phương pháp thu thập dữ liệu tự động là yếu tố quyết định chất lượng và tốc độ xử lý thông tin. Mỗi phương pháp có đặc điểm kỹ thuật và mục đích sử dụng riêng. Dưới đây là các hình thức thu thu thập dữ liệu tự động phổ biến.
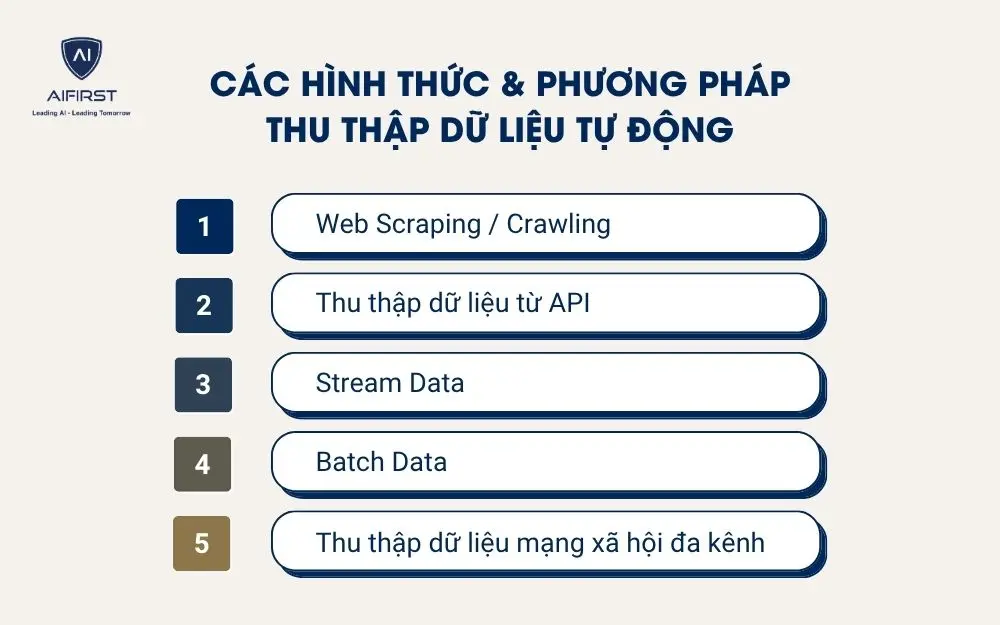
Các hình thức và phương pháp thu thập dữ liệu tự động:
- Web Scraping / Crawling: Phương thức này cho phép thu thập dữ liệu ở quy mô lớn, linh hoạt theo cấu trúc từng trang web và có thể cập nhật định kỳ, phù hợp để tổng hợp thông tin sản phẩm, giá bán hoặc xu hướng nội dung trên Internet.
- Thu thập dữ liệu từ API: Phương pháp này sử dụng API để kết nối trực tiếp giữa các hệ thống, giúp trao đổi và đồng bộ dữ liệu hoàn toàn tự động.
- Stream Data: Stream Data là hình thức thu thập và xử lý dữ liệu ngay khi nó phát sinh, hoạt động liên tục 24/7.
- Batch Data: Là phương thức tổng hợp và xử lý dữ liệu theo chu kỳ định kỳ như hàng giờ, hàng ngày hoặc hàng tuần.
- Thu thập dữ liệu mạng xã hội đa kênh: Phương pháp này tự động quét và thu thập dữ liệu công khai từ nhiều nền tảng mạng xã hội như Facebook, TikTok, Instagram, LinkedIn hay YouTube.
4.1. Web scraping / crawling
Web Scraping là quá trình sử dụng công cụ hoặc bot tự động để trích xuất dữ liệu từ các website công khai, trong khi Web Crawling là hoạt động mở rộng hơn quét qua nhiều trang web để thu thập dữ liệu ở quy mô lớn. Phương pháp này thường được dùng để thu thập thông tin sản phẩm, giá bán, hoặc xu hướng thị trường từ Internet.
- Tự động quét website: Hệ thống bot truy cập, phân tích cấu trúc HTML và trích xuất nội dung theo yêu cầu.
- Thu thập dữ liệu công khai: Áp dụng với các trang web không yêu cầu quyền truy cập đặc biệt.
- Linh hoạt theo nhu cầu: Có thể tùy chỉnh để lấy đúng dữ liệu cần thiết (tên sản phẩm, giá, hình ảnh, bình luận…).
- Thu thập quy mô lớn: Có thể xử lý hàng nghìn trang web hoặc hàng triệu bản ghi dữ liệu mỗi ngày.
- Cập nhật định kỳ: Dữ liệu có thể được thu thập hàng ngày, hàng tuần hoặc theo thời gian thực tùy thiết lập.
4.2. Thu thập dữ liệu từ API
API là cầu nối giúp các hệ thống phần mềm tự động trao đổi dữ liệu với nhau mà không cần thao tác thủ công. Phương pháp này thường được doanh nghiệp sử dụng để đồng bộ dữ liệu từ nhiều nền tảng như CRM, ERP, hệ thống bán hàng hoặc nền tảng quảng cáo.

- Truy xuất dữ liệu có cấu trúc: API trả về dữ liệu ở định dạng chuẩn (JSON, XML) giúp dễ xử lý và lưu trữ.
- Đảm bảo tính bảo mật: Mỗi API có khóa truy cập (API Key) giúp kiểm soát quyền và hạn chế rủi ro rò rỉ thông tin.
- Cập nhật dữ liệu theo thời gian thực: Mỗi khi có thay đổi, dữ liệu được đồng bộ tức thì giữa các hệ thống.
- Tính ổn định và chính xác cao: Dữ liệu được cung cấp trực tiếp từ nguồn gốc, hạn chế lỗi nhập liệu.
- Khả năng mở rộng: API dễ dàng kết nối với nhiều nền tảng khác nhau, phù hợp cho doanh nghiệp đang mở rộng quy mô.
4.3. Stream data
Stream Data là hình thức thu thập dữ liệu theo luồng, được xử lý ngay tại thời điểm phát sinh. Phương pháp này phù hợp cho các doanh nghiệp cần phản ứng nhanh với các biến động như giao dịch, hành vi người dùng hoặc sự kiện vận hành.
- Xử lý tức thời: Dữ liệu được thu thập và phân tích ngay khi xuất hiện, không qua giai đoạn lưu trữ tạm.
- Dòng dữ liệu liên tục: Hoạt động 24/7, đảm bảo không bỏ lỡ bất kỳ sự kiện hoặc tín hiệu nào.
- Phù hợp với dữ liệu có tốc độ cao: Thường áp dụng cho giao dịch tài chính, IoT, hoặc theo dõi hành vi website.
- Yêu cầu hệ thống ổn định: Cần hạ tầng có khả năng xử lý song song và độ trễ thấp.
- Dễ tích hợp AI: Kết hợp với mô hình AI để phát hiện bất thường hoặc dự đoán hành vi theo thời gian thực.
4.4. Thu thập từ file định kỳ (batch data)
Batch Data là phương pháp thu thập và xử lý dữ liệu theo từng đợt (batch), thường được thực hiện định kỳ như hàng ngày, hàng tuần hoặc hàng tháng. Phương pháp này giúp tổng hợp dữ liệu số lượng lớn mà không gây quá tải cho hệ thống.
- Thu thập dữ liệu theo chu kỳ: Thực hiện xử lý dữ liệu vào thời điểm cố định (ví dụ: 0h mỗi ngày).
- Phù hợp với dữ liệu lớn: Có thể xử lý hàng triệu bản ghi trong mỗi phiên làm việc.
- Tối ưu tài nguyên hệ thống: Dữ liệu được xử lý ngoài giờ cao điểm để tránh làm chậm hệ thống vận hành.
- Dễ quản lý và kiểm soát: Kết quả được tổng hợp thành báo cáo định kỳ, dễ dàng lưu trữ và đối soát.
- Thường dùng trong phân tích chiến lược: Thích hợp để tổng hợp báo cáo doanh thu, chi phí, hoặc KPI định kỳ.
4.5. Thu thập dữ liệu mạng xã hội đa kênh
Social Data Collection là hình thức sử dụng công cụ và AI để tự động quét, thu thập dữ liệu từ nhiều nền tảng mạng xã hội như Facebook, TikTok, Instagram, LinkedIn, YouTube, Zalo…. Đây là nguồn dữ liệu quan trọng giúp doanh nghiệp hiểu rõ hành vi, xu hướng và cảm xúc của khách hàng trên không gian số.

- Tự động quét nội dung công khai: Bao gồm bài viết, bình luận, lượt thích, chia sẻ và hashtag liên quan.
- Đa kênh, đa nguồn: Thu thập đồng thời dữ liệu từ nhiều nền tảng khác nhau trong cùng một hệ thống.
- Lọc dữ liệu theo chủ đề: Có thể thiết lập từ khóa, thương hiệu, hoặc nhóm sản phẩm để thu thập chính xác.
- Dữ liệu cập nhật liên tục: Theo dõi biến động và xu hướng thảo luận theo thời gian thực.
- Phù hợp cho phân tích cảm xúc: Hỗ trợ AI phân tích sentiment (tích cực – tiêu cực – trung lập) để hiểu rõ phản ứng của người dùng.
5. Quy trình triển khai thu thập dữ liệu tự động
Để xây dựng một hệ thống thu thập dữ liệu tự động hiệu quả, doanh nghiệp cần có lộ trình triển khai rõ ràng, kết hợp giữa chiến lược – công nghệ – con người. Một quy trình chuẩn không chỉ đảm bảo dữ liệu được thu thập chính xác, đầy đủ mà còn giúp tiết kiệm chi phí, tăng tốc độ xử lý và tối ưu hiệu quả khai thác sau này.
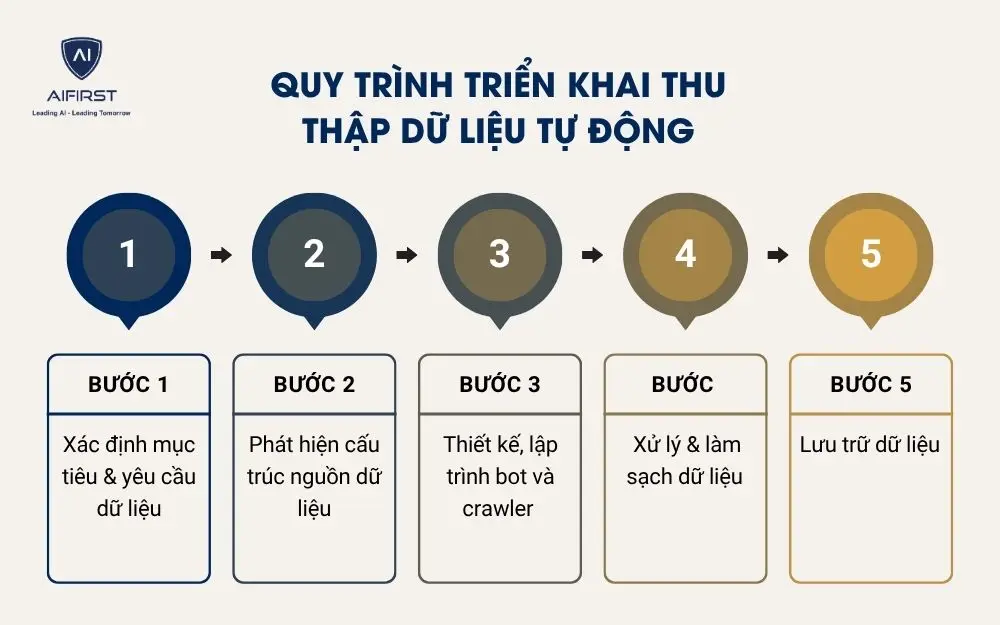
Các bước triển khai thu thập dữ liệu tự động:
- Bước 1: Xác định mục tiêu & yêu cầu dữ liệu
- Bước 2: Phát hiện cấu trúc nguồn dữ liệu
- Bước 3: Thiết kế, lập trình bot và crawler
- Bước 4: Xử lý & làm sạch dữ liệu
- Bước 5: Lưu trữ dữ liệu
Bước 1: Xác định mục tiêu & yêu cầu dữ liệu
Đây là giai đoạn nền tảng giúp doanh nghiệp xác định rõ “vì sao” cần thu thập dữ liệu và “dữ liệu nào” thực sự cần thiết. Một hệ thống dữ liệu chỉ phát huy sức mạnh khi được thiết kế xoay quanh mục tiêu kinh doanh cụ thể (ví dụ như tối ưu bán hàng, nâng cao hiệu quả marketing, hay dự đoán hành vi khách hàng). Nếu bỏ qua bước này, doanh nghiệp sẽ dễ rơi vào tình trạng thu thập dữ liệu dư thừa, gây lãng phí thời gian và chi phí lưu trữ.
- Xác định mục tiêu rõ ràng: Dữ liệu phục vụ cho hoạt động nào? (Marketing, vận hành, chăm sóc khách hàng, tài chính...)
- Khoanh vùng phạm vi dữ liệu: Xác định nhóm dữ liệu trọng tâm như dữ liệu khách hàng, sản phẩm, thị trường hoặc hành vi người dùng.
- Đặt ra KPI cho dữ liệu: Ví dụ: cập nhật theo ngày, độ chính xác trên 95%, số nguồn dữ liệu cần tích hợp.
- Đánh giá nguồn hiện có: Liệt kê các nguồn dữ liệu sẵn có trong hệ thống (CRM, POS, ERP) để tránh thu trùng lặp.
- Xây dựng kế hoạch triển khai tổng thể: Bao gồm ngân sách, thời gian, công cụ, và đội ngũ chịu trách nhiệm quản lý dữ liệu.
Bước 2: Phát hiện cấu trúc nguồn dữ liệu
Sau khi xác định mục tiêu, bước tiếp theo là phân tích nguồn dữ liệu để hiểu rõ cấu trúc, định dạng và cách truy xuất. Mỗi nguồn dữ liệu (website, API, mạng xã hội, cảm biến IoT…) đều có đặc điểm khác nhau, nên việc nhận diện đúng cấu trúc là điều kiện tiên quyết để xây dựng công cụ thu thập phù hợp. Nếu không hiểu cấu trúc nguồn, hệ thống dễ thu sai dữ liệu hoặc gặp lỗi trong quá trình xử lý.

- Liệt kê toàn bộ nguồn dữ liệu: Bao gồm nguồn nội bộ (CRM, ERP, POS) và nguồn bên ngoài (website, sàn TMĐT, mạng xã hội).
- Phân loại theo cấu trúc: Dữ liệu có cấu trúc (SQL, CSV, Excel), dữ liệu bán cấu trúc (Dữ liệu JSON, XML, API endpoint), dữ liệu phi cấu trúc (Hình ảnh, video, bình luận, văn bản tự do).
- Phân tích cấu trúc kỹ thuật: Xác định cách truy xuất dữ liệu – thẻ HTML, endpoint API, đường dẫn tệp, hoặc query database.
- Đánh giá độ tin cậy của nguồn: Nguồn có được cập nhật thường xuyên không? Có hợp pháp để khai thác không?
- Tạo sơ đồ dòng dữ liệu (Data Flow Map): Giúp đội kỹ thuật hình dung cách dữ liệu di chuyển giữa các hệ thống.
Bước 3: Thiết kế, lập trình bot và crawler
Đây là “trái tim” của quy trình nơi doanh nghiệp xây dựng hệ thống tự động hóa việc thu thập dữ liệu. Dựa trên loại nguồn đã xác định, đội ngũ kỹ thuật sẽ thiết kế các bot (robot tự động), crawler (trình thu thập) để đảm bảo dữ liệu được thu về ổn định, đúng cấu trúc và đúng tần suất mong muốn.
- Lập trình crawler (bot quét web): Viết thuật toán để bot truy cập website, nhận dạng dữ liệu mục tiêu, và trích xuất thông tin cần thiết.
- Kết nối API: Thiết lập kết nối với nền tảng bên thứ ba (Facebook Ads, CRM, Google Analytics…) để lấy dữ liệu chuẩn hóa, an toàn.
- Lên lịch tự động hóa (Scheduler): Cấu hình hệ thống để dữ liệu được thu thập định kỳ (hàng ngày, hàng giờ hoặc theo sự kiện).
- Thiết lập kiểm soát lỗi: Bao gồm phát hiện lỗi kết nối, chống trùng lặp và cơ chế retry khi hệ thống tạm ngắt.
- Tối ưu hiệu suất hệ thống: Đảm bảo tốc độ quét nhanh nhưng không bị chặn IP hoặc làm gián đoạn hoạt động website nguồn.
Bước 4: Xử lý & làm sạch dữ liệu
Sau khi dữ liệu được thu thập, việc xử lý và làm sạch là bước không thể bỏ qua. Dữ liệu “bẩn” tức dữ liệu trùng, sai định dạng hoặc thiếu thông tin sẽ làm sai lệch kết quả phân tích. Đây cũng là bước quan trọng để chuẩn bị dữ liệu cho các hệ thống BI (Business Intelligence) hoặc mô hình AI sau này.
- Phát hiện và loại bỏ dữ liệu trùng: Loại các bản ghi lặp lại hoặc dữ liệu lỗi.
- Chuẩn hóa định dạng: Đưa dữ liệu về cấu trúc thống nhất (ngày tháng, đơn vị, kiểu số liệu).
- Xử lý dữ liệu thiếu: Sử dụng kỹ thuật nội suy hoặc điền giá trị mặc định để đảm bảo dữ liệu đủ cho phân tích.
- Phát hiện và sửa lỗi logic: Ví dụ: khách hàng có tuổi âm, địa chỉ không hợp lệ, số liệu doanh thu vượt ngưỡng bất hợp lý.
- Làm giàu dữ liệu (Data Enrichment): Kết hợp dữ liệu từ nhiều nguồn (ví dụ: thêm nhân khẩu học từ CRM vào dữ liệu hành vi).
- Tự động hóa quá trình làm sạch: Dùng pipeline AI để phát hiện lỗi và xử lý tự động, giảm phụ thuộc vào con người.
Bước 5: Lưu trữ dữ liệu
Sau khi xử lý xong, dữ liệu cần được lưu trữ một cách khoa học, an toàn và dễ truy cập. Đây là nền tảng để doanh nghiệp tận dụng dữ liệu cho các mục tiêu phân tích, báo cáo và ra quyết định chiến lược. Một hệ thống lưu trữ hiện đại không chỉ giúp quản lý dữ liệu hiệu quả mà còn tạo điều kiện cho việc triển khai các ứng dụng AI sau này.

- Phân cấp dữ liệu: Tách rõ dữ liệu thô, dữ liệu đã xử lý và dữ liệu phân tích để dễ quản lý.
- Thiết lập quyền truy cập: Áp dụng phân quyền theo vai trò để đảm bảo bảo mật.
- Đồng bộ hóa với công cụ phân tích: Kết nối dữ liệu với dashboard BI, AI model hoặc hệ thống CRM để khai thác giá trị.
- Bảo mật & sao lưu: Thiết lập cơ chế backup định kỳ và bảo vệ dữ liệu bằng mã hóa, chống rò rỉ hoặc truy cập trái phép.
- Giám sát và tối ưu lưu trữ: Theo dõi dung lượng, tốc độ truy cập, chi phí cloud để tối ưu tài nguyên.
6. Thách thức khi thu thập dữ liệu tự động
Mặc dù thu thập dữ liệu tự động mang lại nhiều lợi ích vượt trội cho doanh nghiệp, nhưng quá trình triển khai thực tế lại không hề đơn giản. Các hệ thống tự động phải đối mặt với nhiều vấn đề kỹ thuật, pháp lý và quản trị dữ liệu. Nếu không được chuẩn bị kỹ lưỡng, doanh nghiệp có thể gặp lỗi thu thập, mất dữ liệu hoặc thậm chí vi phạm quy định bảo mật.
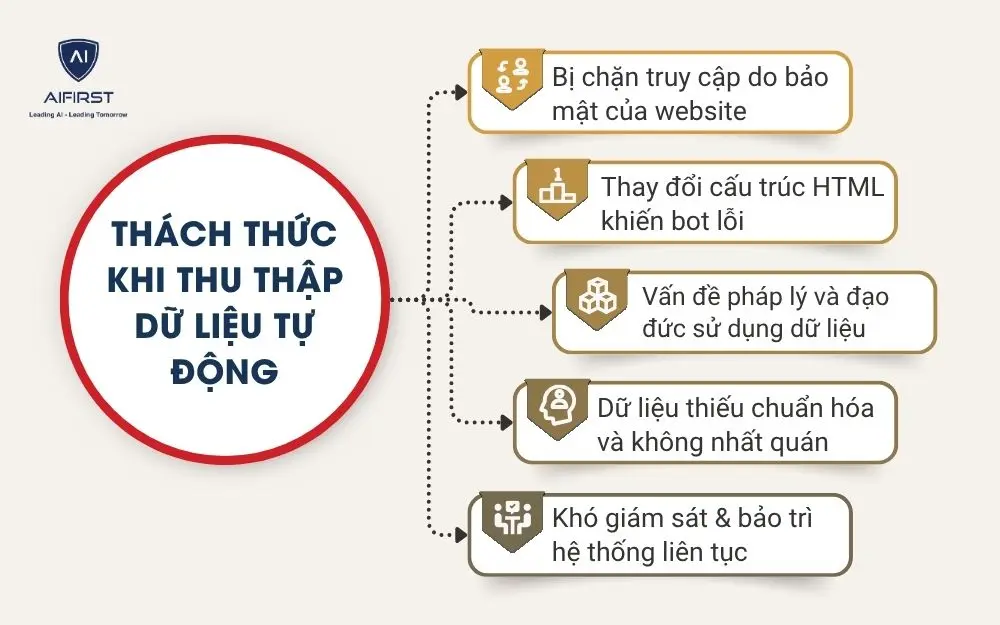
- Bị chặn truy cập do bảo mật của website: Một trong những khó khăn phổ biến nhất khi triển khai web scraping hoặc crawling là bị website nguồn chặn truy cập. Hầu hết các trang web hiện nay đều có cơ chế chống bot và tường lửa bảo mật (firewall) để ngăn các truy vấn tự động.
- Thay đổi cấu trúc HTML khiến bot lỗi: Website thường xuyên được cập nhật, thay đổi bố cục hoặc cấu trúc HTML. Điều này có thể khiến bot thu thập dữ liệu (crawler) không còn nhận dạng đúng phần tử cần lấy dữ liệu, dẫn đến lỗi thu thập hoặc trích xuất sai nội dung. Đây là một trong những nguyên nhân phổ biến khiến hệ thống thu thập dữ liệu tự động bị gián đoạn mà doanh nghiệp khó phát hiện kịp thời.
- Vấn đề pháp lý và đạo đức sử dụng dữ liệu: Một trong những thách thức lớn nhất trong thời đại số là rủi ro pháp lý và đạo đức khi thu thập dữ liệu tự động. Việc thu thập, xử lý và sử dụng dữ liệu từ Internet đặc biệt là dữ liệu cá nhân phải tuân thủ nghiêm ngặt các quy định như GDPR (châu Âu), CCPA (Mỹ), hoặc Luật An ninh mạng & Bảo vệ dữ liệu cá nhân (Việt Nam).
- Dữ liệu thiếu chuẩn hóa và không nhất quán: Ngay cả khi hệ thống thu thập dữ liệu hoạt động tốt, doanh nghiệp vẫn có thể gặp vấn đề dữ liệu không chuẩn hóa hoặc không đồng nhất giữa các nguồn. Điều này thường xảy ra khi dữ liệu được lấy từ nhiều nền tảng có cấu trúc, định dạng hoặc đơn vị đo lường khác nhau.
- Khó giám sát & bảo trì hệ thống liên tục: Hệ thống thu thập dữ liệu tự động cần hoạt động 24/7, đồng nghĩa với việc doanh nghiệp phải giám sát và bảo trì liên tục. Nếu không có quy trình vận hành rõ ràng, hệ thống dễ gặp sự cố mà không được phát hiện kịp thời, gây gián đoạn chuỗi dữ liệu.
Có thể thấy, thu thập dữ liệu tự động không chỉ giúp doanh nghiệp rút ngắn thời gian xử lý thông tin mà còn mở ra khả năng ra quyết định dựa trên dữ liệu chính xác và toàn diện hơn. Tuy nhiên, để triển khai thành công, doanh nghiệp cần có chiến lược rõ ràng, hệ thống công nghệ phù hợp. Qua bài viết trên, AI First sẽ giúp doanh nghiệp trong từng giai đoạn thiết kế đến vận hành hệ thống dữ liệu tự động, giúp doanh nghiệp khai thác triệt để sức mạnh của dữ liệu và vững vàng trên hành trình chuyển đổi số.





