Mục lục [Ẩn]
Trong thời đại dữ liệu bùng nổ, Machine Learning là gì trở thành câu hỏi được nhiều doanh nghiệp, nhà nghiên cứu và cả người dùng phổ thông quan tâm. Việc hiểu rõ Machine Learning không chỉ giúp bạn nắm bắt công nghệ cốt lõi của kỷ nguyên AI, mà còn mở ra cơ hội áp dụng vào kinh doanh và quản trị để tạo lợi thế cạnh tranh bền vững.Cùng AI FIRST khám phá cách ứng dụng học máy này trong bài viết dưới đây.
Những điểm chính trong bài:
- Định nghĩa Machine Learning là gì?
- Sự khác nhau giữa AI, Machine Learning và Deep Learning: Giải thích mối quan hệ ba tầng và bảng so sánh chi tiết.
- 6 bước hoạt động của Machine Learning: Thu thập dữ liệu → Tiền xử lý → Chọn thuật toán → Huấn luyện → Đánh giá → Triển khai & cải tiến.
- Các loại Machine Learning phổ biến hiện nay: Học có giám sát, học không giám sát, học nửa giám sát và học tăng cường
- 5 thuật toán phổ biến trong Machine Learning: Hồi quy tuyến tính, hồi quy logistic, cây quyết định, rừng nhẫu nhiên, mạng nơ-ron nhân tạo
- 6. Ứng dụng Machine Learning trong doanh nghiệp: Marketing, tài chính, chuỗi cung ứng, phân tích khách hàng, quản trị nhân sự, y tế
- Top công cụ Machine Learning được ưa chuộng: TensorFlow, PyTorch, Apache Mahout, Microsoft Azure ML, Vertex AI, Amazon SageMaker.
1. Machine Learning là gì?
Theo MIT, Machine Learning hay (học máy) là một nhánh của trí tuệ nhân tạo (AI), tập trung vào việc phát triển các thuật toán và hệ thống có thể tự động học hỏi từ dữ liệu và kinh nghiệm để cải thiện hiệu suất, mà không cần lập trình trực tiếp cho từng nhiệm vụ. Nói cách khác, thay vì lập trình từng bước logic, con người cung cấp cho học máy dữ liệu và thuật toán để học máy tự rút ra quy luật và cải thiện hiệu suất theo thời gian.
Ví dụ: Các thuật toán Machine Learning có thể học cách phân loại Email, xác định đâu là thư rác (spam) và đâu là thư quan trọng.

2. Cách thức hoạt động của Machine learning
ML hoạt động dựa trên một chuỗi các bước lặp lại. Quá trình này diễn ra tuần tự từ việc thu thập dữ liệu, làm sạch, chọn thuật toán, đến huấn luyện, đánh giá và triển khai vào thực tiễn.
Dưới đây là cách thức hoạt động của Machine Learning:

- Thu thập dữ liệu: Quá trình học của máy bắt đầu từ việc thu thập dữ liệu. Đây có thể là con số, văn bản, hình ảnh, video hoặc tín hiệu cảm biến. Dữ liệu càng đa dạng và phong phú thì mô hình càng có cơ hội học tốt. Giống như con người học từ trải nghiệm, máy tính cũng chỉ có thể “học” khi có dữ liệu để quan sát.
- Tiền xử lý dữ liệu: Không phải dữ liệu nào cũng “sạch” và sẵn sàng để sử dụng. Máy tính cần một bước tiền xử lý, bao gồm việc loại bỏ dữ liệu trùng lặp, xử lý giá trị bị thiếu, chuẩn hóa định dạng và biến đổi dữ liệu về dạng có thể đưa vào mô hình. Nếu dữ liệu là nguyên liệu, thì tiền xử lý chính là công đoạn “lọc và chế biến” để đảm bảo nguyên liệu đủ chất lượng cho quá trình huấn luyện.
- Chọn thuật toán: Mỗi loại bài toán khác nhau sẽ phù hợp với những thuật toán khác nhau. Nếu cần dự đoán giá nhà dựa trên diện tích và vị trí, ta có thể dùng Linear Regression. Nếu cần phân loại email thành “spam” và “không spam”, ta có thể chọn Decision Trees hoặc Random Forest. Lựa chọn thuật toán giống như chọn phương pháp học: đúng cách sẽ giúp mô hình học nhanh và hiệu quả hơn.
- Huấn luyện mô hình: Ở bước này, dữ liệu huấn luyện sẽ được đưa vào thuật toán để máy tính học mối quan hệ giữa đầu vào (input) và đầu ra (output). Quá trình này diễn ra nhiều lần, máy liên tục điều chỉnh tham số bên trong để giảm sai số. Có thể hình dung bước này giống như học sinh làm nhiều bài tập: càng luyện tập nhiều, kết quả càng tiến bộ.
- Đánh giá mô hình: Sau khi huấn luyện, mô hình cần được kiểm tra bằng một tập dữ liệu mới chưa từng thấy trước đó (test data). Đây là cách để đánh giá xem mô hình có thật sự hiểu bản chất vấn đề hay chỉ “học thuộc lòng” dữ liệu cũ. Các chỉ số như độ chính xác (accuracy), sai số (error rate) hay độ khái quát hóa sẽ được sử dụng để đo lường hiệu quả.
- Triển khai và cải tiến: Khi mô hình đã đạt chất lượng mong muốn, nó sẽ được triển khai trong thực tế, chẳng hạn như phân loại email spam, gợi ý sản phẩm, hay nhận diện giọng nói. Tuy nhiên, dữ liệu và môi trường luôn thay đổi, vì vậy mô hình cũng cần được cập nhật và huấn luyện lại thường xuyên. Đây là quá trình cải tiến liên tục để mô hình luôn giữ được độ chính xác và tính hữu dụng.
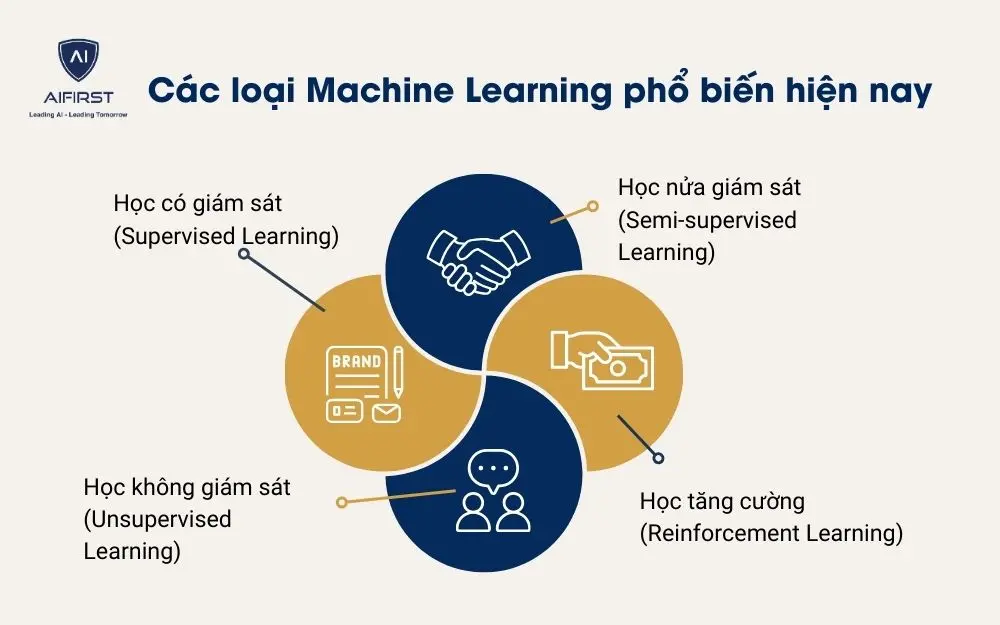
3. Các loại Machine Learning phổ biến hiện nay
Machine Learning có nhiều phương pháp khác nhau, mỗi phương pháp phù hợp với loại dữ liệu và yêu cầu khác nhau của bài toán. Các phương pháp này giúp máy tính học hỏi từ dữ liệu để đưa ra quyết định hoặc dự đoán chính xác, từ đó tối ưu hóa các quy trình và ứng dụng trong nhiều lĩnh vực. Dước đây là các loại ML phổ biến:
- Học có giám sát
- Học không giám sát
- Học nửa giám sát
- Học tăng cường
3.1. Học có giám sát (Supervised Learning)
Học có giám sát là phương pháp sử dụng hệ thống học từ dữ liệu đã được gán nhãn (dữ liệu huấn luyện). Mô hình sẽ được huấn luyện với các ví dụ đầu vào và đầu ra để học cách dự đoán kết quả cho dữ liệu mới.
Ví dụ: Trong phân loại Email, mô hình học có giám sát có thể được huấn luyện với dữ liệu thư rác và không phải thư rác. Từ đó, tự động phân loại các Email mới.
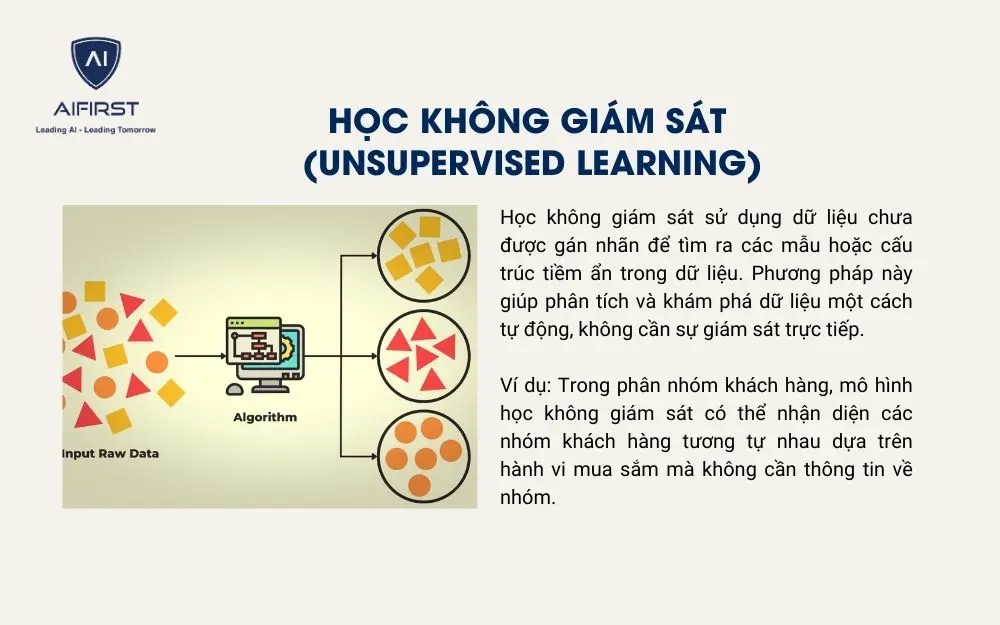
3.2. Học không giám sát (Unsupervised Learning)
Học không giám sát sử dụng dữ liệu chưa được gán nhãn để tìm ra các mẫu hoặc cấu trúc tiềm ẩn trong dữ liệu. Phương pháp này giúp phân tích và khám phá dữ liệu một cách tự động, không cần sự giám sát trực tiếp.
Ví dụ: Trong phân nhóm khách hàng, mô hình học không giám sát có thể nhận diện các nhóm khách hàng tương tự nhau dựa trên hành vi mua sắm mà không cần thông tin về nhóm.
3.3. Học nửa giám sát (Semi-supervised Learning)
Học nửa giám sát kết hợp dữ liệu đã được gán nhãn và chưa gán nhãn để tạo ra mô hình học hiệu quả hơn. Phương pháp này thường được sử dụng khi có ít dữ liệu đã được gán nhãn nhưng vẫn cần phải tận dụng dữ liệu chưa có nhãn.
Ví dụ: Một mô hình nhận diện hình ảnh có thể được huấn luyện với một số ảnh đã được gán nhãn và hàng nghìn ảnh chưa nhãn để cải thiện độ chính xác.
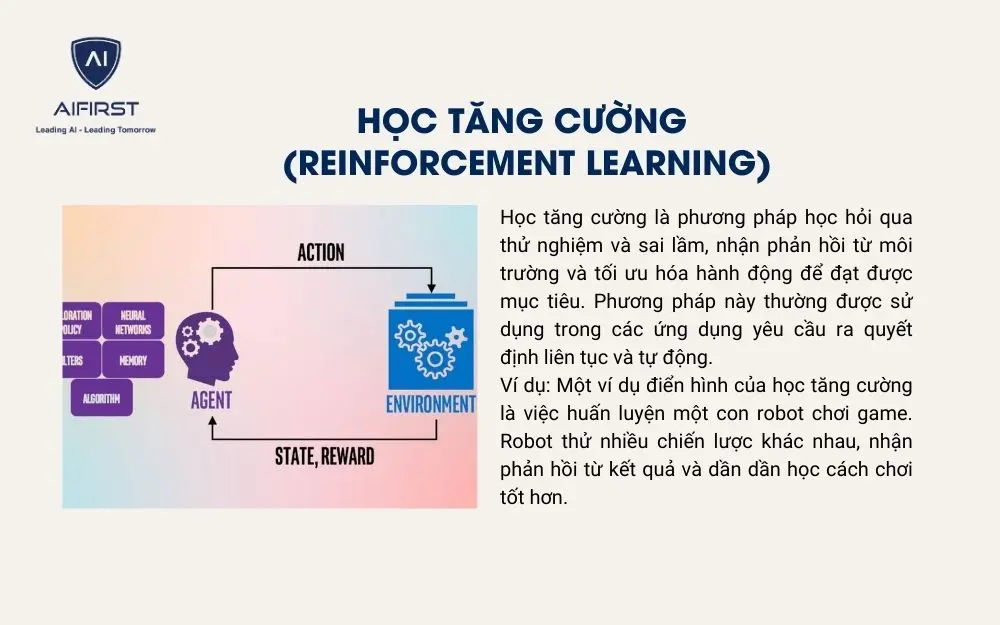
3.4. Học tăng cường (Reinforcement Learning)
Học tăng cường là phương pháp học hỏi qua thử nghiệm và sai lầm, nhận phản hồi từ môi trường và tối ưu hóa hành động để đạt được mục tiêu. Phương pháp này thường được sử dụng trong các ứng dụng yêu cầu ra quyết định liên tục và tự động.
Ví dụ: Một ví dụ điển hình của học tăng cường là việc huấn luyện một con robot chơi game. Robot thử nhiều chiến lược khác nhau, nhận phản hồi từ kết quả và dần dần học cách chơi tốt hơn.
4. Sự khác nhau giữa AI, Machine Learning và Deep Learning
Nhiều người thường nhầm lẫn AI, Machine Learning và Deep Learning là một, nhưng thực tế chúng giống như ba “tầng” khác nhau. Bạn có thể hình dung: AI là chiếc ô lớn bao trùm toàn bộ trí tuệ nhân tạo, Machine Learning là một phần của AI giúp máy móc học từ dữ liệu, còn Deep Learning lại là cách học hiện đại và mạnh mẽ nhất trong Machine Learning. Bảng dưới đây sẽ giúp bạn thấy rõ sự khác biệt giữa ba khái niệm này:
|
Tiêu chí |
AI (Artificial Intelligence) |
ML (Machine Learning) |
DL (Deep Learning) |
|
Định nghĩa |
Ngành khoa học máy tính tạo ra hệ thống có khả năng mô phỏng trí tuệ con người (suy nghĩ, lập luận, quyết định, giao tiếp). |
Nhánh của AI, giúp máy học từ dữ liệu để dự đoán hoặc ra quyết định mà không cần lập trình chi tiết. |
Nhánh của ML, dùng mạng nơ-ron nhiều tầng để xử lý dữ liệu phức tạp và trích xuất đặc trưng. |
|
Phạm vi |
Rộng nhất, bao gồm nhiều lĩnh vực: Robotics, NLP, Computer Vision, Expert Systems, ML… |
Hẹp hơn, tập trung vào thuật toán học từ dữ liệu. |
Hẹp nhất, chuyên biệt cho dữ liệu lớn và phức tạp. |
|
Nguyên lý |
Mô phỏng tư duy và hành vi trí tuệ con người. |
Sử dụng thuật toán và dữ liệu để học mối quan hệ đầu vào – đầu ra. |
Sử dụng mạng nơ-ron nhân tạo nhiều lớp (Deep Neural Networks). |
|
Dữ liệu yêu cầu |
Có thể ít hoặc nhiều, tùy ứng dụng. |
Cần nhiều dữ liệu để huấn luyện tốt. |
Cần dữ liệu khổng lồ (Big Data) và hạ tầng tính toán mạnh (GPU/TPU). |
|
Độ phức tạp |
Cao, bao trùm nhiều công nghệ khác nhau. |
Trung bình đến cao, tùy thuật toán. |
Rất cao, yêu cầu mô hình lớn và nhiều tài nguyên. |
|
Ứng dụng |
Trợ lý ảo Siri, robot thông minh, xe tự lái, hệ chuyên gia. |
Gợi ý sản phẩm Amazon/Netflix, phân loại email spam, dự báo nhu cầu. |
Nhận diện khuôn mặt, dịch ngôn ngữ tự động, ChatGPT, xe tự lái Tesla. |
|
Ví dụ minh họa |
Robot Sophia, ChatGPT, xe tự lái. |
Bộ lọc email Gmail, hệ thống gợi ý Shopee/Lazada. |
Công nghệ Deepfake, Google Translate, Face ID trên iPhone. |
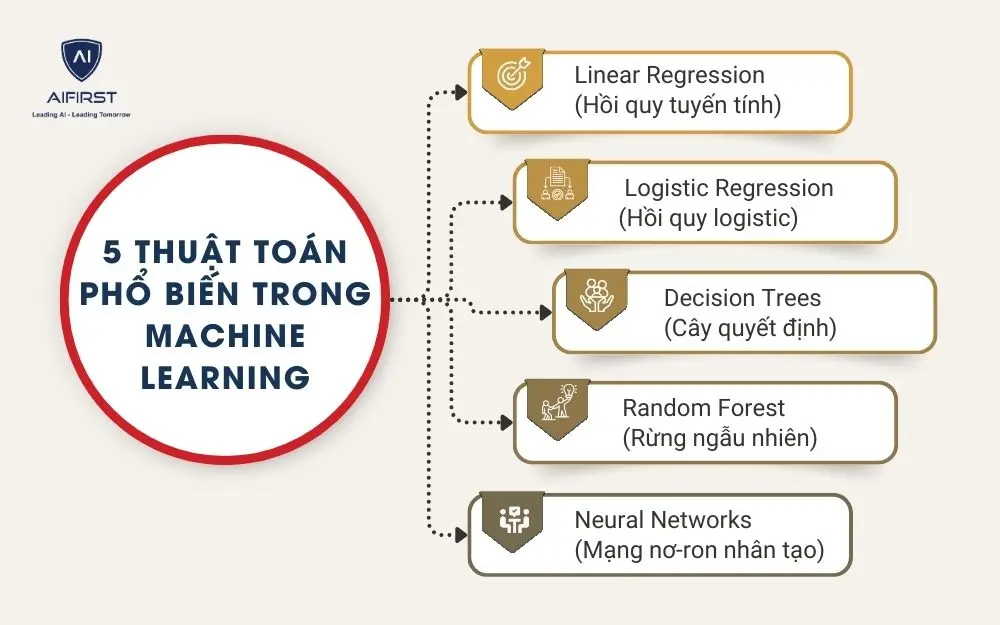
5. 5 thuật toán phổ biến trong Machine Learning
Để Machine Learning có thể “học” và đưa ra dự đoán, thứ quan trọng nhất chính là thuật toán. Mỗi bài toán khác nhau sẽ cần một thuật toán phù hợp: có loại chuyên dự đoán con số, có loại chuyên phân loại, cũng có loại xử lý dữ liệu phức tạp như hình ảnh hay giọng nói. Dưới đây là 5 thuật toán Machine Learning phổ biến và được ứng dụng rộng rãi nhất hiện nay:
- Hồi quy tuyến tính
- Hồi quy logistic
- Cây quyết định
- Rừng ngẫu nhiên
- Mạng nơ-ron nhân tạo
1 - Linear Regression (Hồi quy tuyến tính)
Đây là một trong những thuật toán cơ bản và dễ hiểu nhất. Linear Regression dự đoán giá trị đầu ra dựa trên mối quan hệ tuyến tính giữa các biến đầu vào.
Ví dụ: Dự đoán giá nhà dựa trên diện tích, vị trí và số phòng ngủ. Các sàn BĐS trực tuyến như Zillow sử dụng thuật toán này để ước tính giá trị bất động sản.
2 - Logistic Regression (Hồi quy logistic)
Dù tên có chữ “regression”, nhưng thực chất Logistic Regression là thuật toán phân loại nhị phân (có/không, đúng/sai). Nó dựa trên hàm sigmoid để dự đoán xác suất một sự kiện xảy ra. Hồi quy logistic dùng hàm sigmoid để biến đầu ra thành xác suất (từ 0 đến 1), thường áp dụng cho bài toán phân loại nhị phân (có/không, đúng/sai).
Ví dụ: Gmail dùng Logistic Regression để phân loại email thành “spam” hoặc “không spam”.
3 - Decision Trees (Cây quyết định)
Dữ liệu được chia thành các nhánh dựa trên điều kiện (if-then). Mỗi nút đại diện cho một thuộc tính, mỗi nhánh là điều kiện, và lá cuối cùng là kết quả dự đoán. Thuật toán này chia nhỏ dữ liệu thành các “nhánh” dựa trên điều kiện, giống như một sơ đồ ra quyết định. Dễ hiểu, trực quan, và thường được dùng cho cả phân loại và hồi quy.
Ví dụ: Các ngân hàng dùng Decision Trees để đánh giá khả năng cấp tín dụng, dựa trên các yếu tố như thu nhập, lịch sử tín dụng, nghề nghiệp.
4 - Random Forest (Rừng ngẫu nhiên)
Random Forest là tập hợp nhiều Decision Trees. Thay vì dựa vào một cây đơn lẻ, nó kết hợp kết quả từ nhiều cây để tăng độ chính xác và giảm sai số.
Ví dụ: Amazon áp dụng Random Forest để gợi ý sản phẩm, dựa trên lịch sử mua hàng và hành vi của hàng triệu người dùng.
5 - Neural Networks (Mạng nơ-ron nhân tạo)
Đây là nền tảng cho Deep Learning. Neural Networks mô phỏng cách hoạt động của não người, với nhiều “nơ-ron” nhân tạo kết nối thành các lớp. Rất mạnh trong việc xử lý dữ liệu phức tạp như hình ảnh, giọng nói, văn bản.
Ví dụ: Facebook dùng Neural Networks để tự động gắn thẻ khuôn mặt trong ảnh, Google Translate dùng để dịch văn bản theo ngữ cảnh.
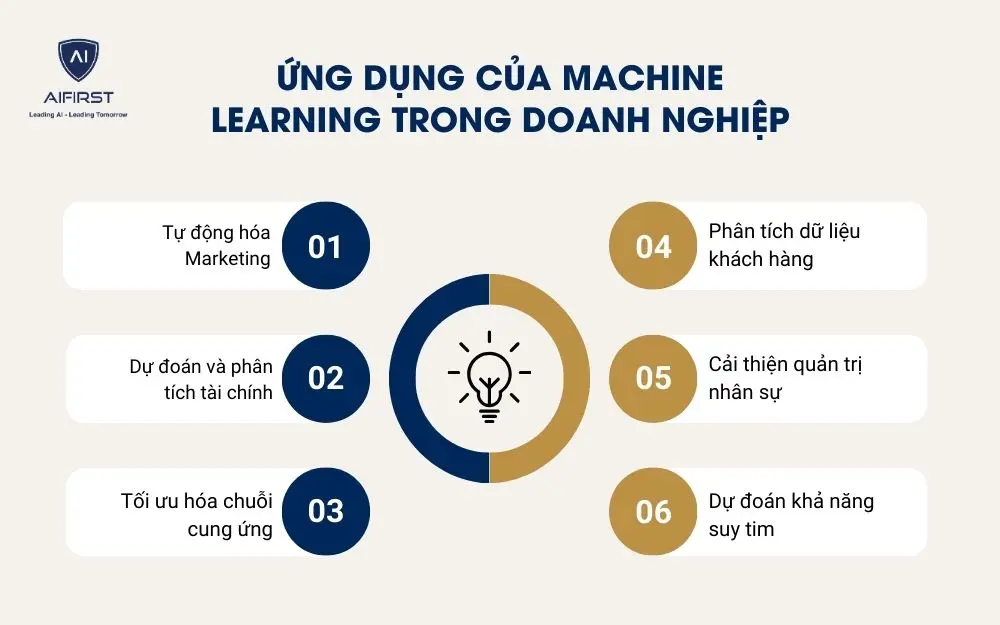
6. Một số ứng dụng phổ biến của Machine Learning
Nhờ khả năng phân tích dữ liệu lớn và học hỏi tự động, Machine Learning giúp doanh nghiệp cải thiện hiệu quả công việc và ra quyết định chính xác hơn. Các ứng dụng của Machine Learning có thể được thấy trong nhiều lĩnh vực khác nhau, từ Marketing, tài chính đến y tế và sản xuất. Dưới đây là các ứng dụng phổ biến của Machine Learning:
- Tự động hóa Marketing
- Dự đoán và phân tích tài chính
- Tối ưu hóa chuỗi cung ứng
- Phân tích dữ liệu khách hàng
- Cải thiện quản trị nhân sự
- Dự đoán khả năng suy tim
6.1. Tự động hóa Marketing
Machine Learning hỗ trợ doanh nghiệp tự động hóa các chiến dịch Marketing bằng cách phân tích hành vi và sở thích của khách hàng thông qua dữ liệu thu thập từ nhiều nguồn (như mạng xã hội, lịch sử mua hàng và các tương tác trực tuyến). Các thuật toán học máy có thể nhận diện mẫu hành vi của khách hàng, phân loại họ thành các nhóm mục tiêu và tạo ra các chiến dịch Marketing cá nhân hóa.
Ví dụ: Netflix áp dụng Machine Learning để gợi ý phim cá nhân hóa. Hệ thống phân tích lịch sử xem phim, thời lượng xem và đánh giá của hàng trăm triệu người dùng, từ đó đề xuất nội dung phù hợp. Theo báo cáo của Netflix, hơn 80% nội dung được xem đến từ hệ thống gợi ý này, giúp giữ chân khách hàng lâu hơn.
6.2. Dự đoán và phân tích tài chính
Bằng cách xử lý lượng lớn dữ liệu từ nhiều nguồn khác nhau như giá cổ phiếu, tỷ giá hối đoái và báo cáo tài chính, các mô hình máy học có khả năng:

- Phát hiện sớm các tín hiệu thay đổi của thị trường: Máy học có thể nhận diện các mẫu hình và xu hướng ẩn sâu trong dữ liệu, giúp nhà đầu tư nắm bắt kịp thời những biến động sắp xảy ra.
- Dự đoán biến động giá trị tài sản: Các thuật toán Machine Learning có thể dự báo sự tăng giảm của giá cổ phiếu, trái phiếu, tiền tệ và các loại tài sản khác, hỗ trợ nhà đầu tư đưa ra quyết định mua bán thông minh.
- Hỗ trợ ra quyết định chiến lược: Dựa trên những phân tích và dự đoán từ học máy, nhà đầu tư có thể xây dựng chiến lược đầu tư hiệu quả, tối ưu hóa lợi nhuận và giảm thiểu rủi ro.
Ví dụ: PayPal sử dụng Machine Learning để phát hiện gian lận giao dịch. Hệ thống có khả năng phân tích hàng tỷ giao dịch mỗi năm, học từ các mẫu gian lận cũ để nhận diện bất thường mới. Nhờ đó, PayPal đã giảm mạnh tỷ lệ gian lận và bảo vệ an toàn cho hơn 400 triệu người dùng.
6.3. Tối ưu hóa chuỗi cung ứng
Machine Learning hỗ trợ doanh nghiệp tối ưu hóa chuỗi cung ứng thông qua việc phân tích dữ liệu về sản xuất, lưu kho, vận chuyển và nhu cầu thị trường. Các mô hình học máy có thể dự đoán nhu cầu sản phẩm, xác định thời điểm tốt nhất để đặt hàng lại cũng như tối ưu hóa lộ trình vận chuyển để giảm thiểu chi phí.
Ví dụ: Amazon ứng dụng Machine Learning trong hệ thống dự báo nhu cầu sản phẩm. Họ có thể biết khách hàng ở New York hay Tokyo sắp đặt hàng gì trước khi họ bấm “mua”. Điều này cho phép Amazon chuẩn bị sẵn hàng hóa tại kho gần khách hàng nhất, giúp giao hàng trong 1–2 ngày với Amazon Prime và giảm đáng kể chi phí logistics.
6.4. Phân tích dữ liệu khách hàng
Công nghệ học máy phân tích các mẫu hành vi của khách hàng từ dữ liệu thu thập được để tạo ra các chiến lược bán hàng chính xác hơn. Bằng cách nhận diện các nhóm khách hàng có đặc điểm chung, doanh nghiệp có thể tối ưu hóa dịch vụ và sản phẩm theo từng phân khúc.
Ví dụ: Starbucks dùng Machine Learning trong chương trình Starbucks Rewards. Ứng dụng phân tích dữ liệu mua hàng (giờ mua, địa điểm, loại đồ uống) để gửi ưu đãi đúng sở thích, ví dụ: “giảm giá cà phê latte buổi sáng tại cửa hàng bạn thường ghé”. Cách cá nhân hóa này đã giúp Starbucks tăng doanh thu từ khách hàng trung thành lên 40%.

6.5. Cải thiện quản trị nhân sự
Các dữ liệu về nhân viên, hiệu suất làm việc và thói quen làm việc có thể được phân tích để dự đoán sự thay đổi trong lực lượng lao động. Nhờ ứng dụng Machine Learning, doanh nghiệp xác định những nhân viên có nguy cơ nghỉ việc, từ đó đưa ra các biện pháp hỗ trợ kịp thời. Ngoài ra, dữ liệu này cũng có thể được sử dụng để tối ưu hóa các chiến lược đào tạo và phát triển nhân viên, cải thiện hiệu quả làm việc và giảm tỷ lệ nghỉ việc.
Ví dụ: IBM phát triển công cụ Watson Talent để phân tích dữ liệu nhân sự và dự đoán nhân viên nào có nguy cơ nghỉ việc. Theo CEO IBM Ginni Rometty, công cụ này có độ chính xác 95% trong việc dự đoán ý định nghỉ việc, giúp công ty đưa ra biện pháp giữ chân nhân sự hiệu quả.
6.6. Dự đoán khả năng suy tim
Machine Learning cũng có ứng dụng quan trọng trong y tế, đặc biệt là trong việc dự đoán tình trạng bệnh lý như suy tim. Các công nghệ học máy AI chẩn đoán bệnh có thể phân tích dữ liệu y tế của bệnh nhân, bao gồm huyết áp, nhịp tim và các chỉ số sinh tồn khác để phát hiện các dấu hiệu sớm của suy tim.
Ví dụ: Mayo Clinic (Mỹ) triển khai Machine Learning để phân tích dữ liệu điện tâm đồ (ECG) và hồ sơ bệnh án. Công nghệ này có thể phát hiện sớm nguy cơ suy tim trước khi triệu chứng xuất hiện.Thử nghiệm thực tế cho thấy, thuật toán giúp bác sĩ chẩn đoán sớm bệnh nhân có nguy cơ cao, từ đó tăng tỷ lệ điều trị thành công và cứu sống hàng nghìn ca mỗi năm.
7. Top 6 công cụ Machine Learning được ưa chuộng nhất hiện nay
Với sự phát triển mạnh mẽ của công nghệ, Machine Learning đang ngày càng trở thành công cụ quan trọng giúp doanh nghiệp tối ưu hóa quy trình và đưa ra những quyết định thông minh. Dưới đây là 8 công cụ Machine Learning phổ biến và được ưa chuộng nhất hiện nay:
7.1. TensorFlow
TensorFlow là một thư viện mã nguồn mở do Google phát triển, hỗ trợ xây dựng và triển khai các mô hình học sâu (Deep Learning) trên nhiều nền tảng.
Tính năng nổi bật:
- Hỗ trợ cả huấn luyện và triển khai mô hình trên nhiều thiết bị.
- Cung cấp API cho nhiều ngôn ngữ lập trình như Python, C++ và Java.
- Tích hợp với Keras, giúp việc xây dựng mô hình trở nên dễ dàng.
- Có khả năng mở rộng từ các mô hình nhỏ đến các hệ thống phân tán quy mô lớn.
Nhược điểm:
- Đường cong học tập tương đối dốc đối với người mới bắt đầu.
- Cấu hình và triển khai có thể phức tạp đối với các dự án nhỏ.
7.2. Apache Mahout
Apache Mahout là một framework học máy mã nguồn mở, sử dụng ngôn ngữ Scala và chạy trên Apache Hadoop. Nó cung cấp các công cụ để xây dựng các thuật toán đại số tuyến tính phân tán, phù hợp cho việc xử lý dữ liệu lớn.

Tính năng nổi bật:
- Cung cấp các thuật toán học máy như phân cụm, phân loại và hợp nhất.
- Tích hợp chặt chẽ với Apache Hadoop và Spark cho xử lý dữ liệu phân tán.
- Hỗ trợ các mô hình học máy quy mô lớn và phân tán.
- Được tối ưu hóa cho việc xử lý dữ liệu lớn và phân tán.
Nhược điểm:
- Yêu cầu kiến thức vững về Hadoop và Spark để triển khai hiệu quả.
- Cộng đồng hỗ trợ nhỏ hơn so với các công cụ học máy khác.
7.3. PyTorch
PyTorch được thiết kế với sự linh hoạt tối đa, cho phép các nhà nghiên cứu dễ dàng thử nghiệm các ý tưởng mới và phát triển các mô hình đột phá.
Tính năng nổi bật:
- Hỗ trợ tính toán động, cho phép thay đổi cấu trúc mô hình trong quá trình huấn luyện.
- Cung cấp giao diện thân thiện và dễ sử dụng.
- Tích hợp tốt với các thư viện Python khác như NumPy.
- Được sử dụng rộng rãi trong nghiên cứu và phát triển AI.
Nhược điểm:
- Thiếu một số tính năng hỗ trợ triển khai sản xuất so với TensorFlow.
- Yêu cầu phần cứng mạnh mẽ để xử lý các mô hình phức tạp.
7.4. Microsoft Azure Machine Learning
Microsoft Azure Machine Learning tích hợp chặt chẽ với các dịch vụ khác của Azure, tạo ra một hệ sinh thái mạnh mẽ cho việc phát triển và triển khai các ứng dụng trí tuệ nhân tạo.
Tính năng nổi bật:
- Cung cấp môi trường phát triển tích hợp với hỗ trợ đa dạng các framework học máy.
- Hỗ trợ tự động hóa quy trình học máy và triển khai mô hình.
- Tích hợp với các dịch vụ đám mây của Microsoft như Azure Databricks.
- Cung cấp các công cụ giám sát và quản lý mô hình sau khi triển khai.
Nhược điểm:
- Chi phí có thể tăng cao đối với các dự án quy mô lớn.
- Yêu cầu kiến thức về nền tảng Azure để tận dụng tối đa các tính năng.
7.5. Vertex AI
Vertex AI là một nền tảng học máy mạnh mẽ và linh hoạt, cho phép bạn mở rộng quy mô dự án AI của mình một cách dễ dàng.
Tính năng nổi bật:
- Hỗ trợ toàn bộ vòng đời phát triển mô hình học máy.
- Tích hợp với các dịch vụ khác của Google Cloud như BigQuery và Dataflow.
- Cung cấp các công cụ tự động hóa và tối ưu hóa quy trình học máy.
- Hỗ trợ triển khai mô hình trên các thiết bị đầu cuối và môi trường đám mây.
Nhược điểm:
- Yêu cầu hiểu biết về các dịch vụ của Google Cloud để sử dụng hiệu quả.
- Chi phí có thể tăng nhanh khi mở rộng quy mô dự án.
7.6. Amazon SageMaker
Amazon SageMaker AI là nền tảng học máy đám mây của AWS, cho phép xây dựng, huấn luyện và triển khai mô hình học máy, bao gồm cả trên các thiết bị biên.
Tính năng nổi bật:
- Cung cấp môi trường phát triển tích hợp với hỗ trợ nhiều framework học máy.
- Hỗ trợ tự động hóa quy trình huấn luyện và tối ưu hóa mô hình.
- Tích hợp với các dịch vụ AWS khác như S3 và Lambda.
- Cung cấp các công cụ giám sát và quản lý mô hình sau khi triển khai.
Nhược điểm:
- Yêu cầu kiến thức về AWS để sử dụng hiệu quả.
- Chi phí có thể trở thành yếu tố cần cân nhắc đối với các dự án nhỏ.
Hy vọng rằng qua bài viết này, bạn đã hiểu rõ hơn về Machine Learning là gì và sức mạnh của công nghệ này trong việc thúc đẩy sự đổi mới trong doanh nghiệp. Đừng quên theo dõi các chủ đề công nghệ khác mà AI FIRST chia sẻ để không bỏ lỡ những xu hướng mới nhất!






