Mục lục [Ẩn]
AI Databases là một công nghệ quan trọng giúp doanh nghiệp tối ưu hóa việc lưu trữ, xử lý và phân tích dữ liệu lớn cho các ứng dụng trí tuệ nhân tạo (AI). Các cơ sở dữ liệu AI không chỉ giúp quản lý dữ liệu hiệu quả mà còn cải thiện tốc độ và độ chính xác của các mô hình AI. Cùng AI First tìm hiểu chi tiết hơn về AI Databases và cách training AI xây dựng cơ sở dữ liệu giúp doanh nghiệp tận dụng tối đa tiềm năng của dữ liệu để phát triển và cải thiện các chiến lược kinh doanh.
Những ý chính trong bài viết:
- Giải thích AI Databases là gì?
- Lợi ích khi sử dụng AI Databases: Tăng cường hiệu suất và tốc độ xử lý dữ liệu, cải thiện khả năng phân tích và dự báo, tối ưu hóa dữ liệu phi cấu trúc, tính mở rộng và khả năng xử lý khối lượng dữ liệu lớn, hỗ trợ ra quyết định theo thời gian thực.
- Các loại AI Databases: Cơ sở dữ liệu cấu trúc, cơ sở dữ liệu phi cấu trúc, cơ sở dữ liệu bán cấu trúc, cơ sở dữ liệu đồ thị, cơ sở dữ liệu in-memory.
- Quy trình training AI xây dựng database: Từ xác định mục tiêu, thu thập và chuẩn hóa dữ liệu, quản lý dữ liệu, tiến hành training AI, triển khai vào hệ thống đến đánh giá kết quả.
- Các trường hợp cần sử dụng AI Databases: Phát hiện đối tượng và phân tích văn bản, nhận dạng giọng nói, lọc mạng xã hội, kiểm tra bằng mắt thường, xử lý ngôn ngữ tự nhiên.
- Những công cụ hỗ trợ triển khai cơ sở dữ liệu AI: Apache Kafka, TensorFlow Data, Apache Hbase, SpaCy, PyTorch, MLflow.
1. AI Databases là gì?
AI Databases (Cơ sở dữ liệu trí tuệ nhân tạo) là một hệ thống lưu trữ và quản lý dữ liệu được thiết kế đặc biệt để hỗ trợ các ứng dụng và thuật toán trí tuệ nhân tạo (AI). Các cơ sở dữ liệu này giúp tổ chức, lưu trữ và xử lý dữ liệu lớn và phức tạp một cách hiệu quả, từ đó cung cấp nền tảng cho các mô hình AI học máy và phân tích dữ liệu.

Trong các ứng dụng AI, dữ liệu đóng vai trò quan trọng và AI databases cung cấp cơ sở hạ tầng để thu thập, lưu trữ, và quản lý các loại dữ liệu khác nhau, bao gồm dữ liệu không cấu trúc (như văn bản, hình ảnh, video) và dữ liệu có cấu trúc (như bảng dữ liệu). Những cơ sở dữ liệu này thường sử dụng các công nghệ như học máy và xử lý dữ liệu lớn để tối ưu hóa khả năng truy vấn, phân tích và ra quyết định từ dữ liệu.
2. Lợi ích khi sử dụng cơ sở dữ liệu AI
Sử dụng cơ sở dữ liệu AI mang lại nhiều lợi ích quan trọng cho doanh nghiệp trong việc quản lý và xử lý dữ liệu. Dưới đây là những lợi ích nổi bật khi sử dụng cơ sở dữ liệu AI:

- Tăng cường hiệu suất và tốc độ xử lý dữ liệu: Cơ sở dữ liệu AI được tối ưu hóa để xử lý lượng lớn dữ liệu với tốc độ cao, giúp doanh nghiệp tăng cường hiệu suất trong các quy trình phân tích và ra quyết định. Điều này đặc biệt quan trọng trong các lĩnh vực yêu cầu xử lý dữ liệu thời gian thực, như tài chính, chăm sóc sức khỏe và thương mại điện tử.
- Cải thiện khả năng phân tích và dự báo: Cơ sở dữ liệu AI giúp doanh nghiệp khai thác dữ liệu một cách sâu sắc hơn, cung cấp thông tin phân tích chi tiết để hỗ trợ các quyết định chiến lược. Các thuật toán học máy tích hợp trong cơ sở dữ liệu này có thể phân tích xu hướng, dự báo và nhận diện các mẫu dữ liệu quan trọng.
- Tối ưu hóa dữ liệu phi cấu trúc: Dữ liệu phi cấu trúc như văn bản, hình ảnh, và video là một phần quan trọng trong các ứng dụng AI. Cơ sở dữ liệu AI hỗ trợ xử lý và phân tích loại dữ liệu này, giúp doanh nghiệp khai thác thông tin quý giá từ các nguồn dữ liệu không cấu trúc.
- Tính mở rộng và khả năng xử lý khối lượng dữ liệu lớn: Một trong những ưu điểm nổi bật của cơ sở dữ liệu AI là khả năng mở rộng để xử lý khối lượng dữ liệu lớn. Các doanh nghiệp có thể dễ dàng mở rộng hệ thống để phù hợp với sự tăng trưởng dữ liệu, đảm bảo khả năng xử lý và lưu trữ không bị gián đoạn.
- Hỗ trợ ra quyết định theo thời gian thực: Cơ sở dữ liệu AI cho phép doanh nghiệp ra quyết định nhanh chóng và chính xác dựa trên dữ liệu thời gian thực. Với khả năng xử lý dữ liệu tức thì, các doanh nghiệp có thể phản ứng nhanh với các thay đổi trong môi trường kinh doanh và tối ưu hóa các chiến lược.
3. Các loại AI Databases phổ biến hiện nay
AI Databases (Cơ sở dữ liệu trí tuệ nhân tạo) có nhiều loại khác nhau, mỗi loại được thiết kế để xử lý một kiểu dữ liệu và ứng dụng cụ thể trong các mô hình trí tuệ nhân tạo. Mỗi loại cơ sở dữ liệu có những đặc điểm và lợi ích riêng, giúp tối ưu hóa hiệu suất và khả năng xử lý dữ liệu trong các ứng dụng AI.

Các loại AI Databases phổ biến:
- Cơ sở dữ liệu cấu trúc: Lưu trữ dữ liệu có cấu trúc trong các bảng với hàng và cột. Thường sử dụng SQL và RDBMS như MySQL, PostgreSQL.
- Cơ sở dữ liệu phi cấu trúc: Xử lý dữ liệu không có định dạng cố định như văn bản, hình ảnh, video.
- Cơ sở dữ liệu bán cấu trúc: Kết hợp giữa dữ liệu có cấu trúc và không cấu trúc, ví dụ JSON và XML.
- Cơ sở dữ liệu đồ thị: Lưu trữ và xử lý dữ liệu dạng đồ thị, sử dụng các đỉnh và cạnh để thể hiện mối quan hệ.
- Cơ sở dữ liệu in-memory: Lưu trữ dữ liệu trong bộ nhớ RAM thay vì ổ đĩa, giúp tăng tốc độ truy cập và xử lý dữ liệu.
3.1. Cơ sở dữ liệu cấu trúc
Cơ sở dữ liệu cấu trúc (Structured Databases) là những cơ sở dữ liệu truyền thống, nơi dữ liệu được lưu trữ trong các bảng với các hàng và cột. Các cơ sở dữ liệu này thường sử dụng các hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) như MySQL, PostgreSQL, và Oracle để lưu trữ và quản lý dữ liệu có cấu trúc.
Đặc điểm nổi bật:
- Lưu trữ dữ liệu có cấu trúc: Dữ liệu được tổ chức thành các bảng với các trường dữ liệu xác định.
- Dễ dàng truy vấn và quản lý: Dữ liệu có cấu trúc giúp việc tìm kiếm và truy vấn trở nên đơn giản và nhanh chóng.
- Sử dụng SQL: Hệ thống sử dụng SQL để truy vấn và quản lý dữ liệu, dễ dàng tích hợp với các công cụ phân tích dữ liệu.
- Hiệu quả với dữ liệu dạng bảng: Phù hợp với các ứng dụng yêu cầu xử lý dữ liệu có cấu trúc như tài chính, bán hàng, và quản lý khách hàng.
3.2. Cơ sở dữ liệu phi cấu trúc
Cơ sở dữ liệu phi cấu trúc (Unstructured Databases) là các hệ thống lưu trữ và quản lý dữ liệu không có cấu trúc cố định, bao gồm các dạng dữ liệu như văn bản, hình ảnh, video và âm thanh. Đây là loại cơ sở dữ liệu phổ biến cho các ứng dụng AI liên quan đến phân tích ngữ nghĩa, nhận diện hình ảnh, và các bài toán xử lý dữ liệu phi cấu trúc.

Đặc điểm nổi bật:
- Lưu trữ dữ liệu không có cấu trúc: Xử lý các loại dữ liệu không có định dạng cụ thể như văn bản, hình ảnh, video.
- Phân tích dữ liệu phi cấu trúc: Hỗ trợ các công nghệ AI như xử lý ngôn ngữ tự nhiên (NLP) và nhận diện hình ảnh.
- Tích hợp với các công cụ AI: Thường được sử dụng trong các ứng dụng AI yêu cầu phân tích và xử lý dữ liệu phi cấu trúc.
- Khả năng mở rộng linh hoạt: Có thể xử lý khối lượng dữ liệu lớn và đa dạng mà không cần một cấu trúc cố định.
3.3. Cơ sở dữ liệu bán cấu trúc
Cơ sở dữ liệu bán cấu trúc (Semi-Structured Databases) là loại cơ sở dữ liệu kết hợp giữa dữ liệu có cấu trúc và không có cấu trúc. Dữ liệu trong loại cơ sở dữ liệu này không được tổ chức thành các bảng như cơ sở dữ liệu cấu trúc, nhưng vẫn có một số tổ chức hoặc mối quan hệ, ví dụ như JSON hoặc XML.
Đặc điểm nổi bật:
- Lưu trữ dữ liệu không hoàn toàn cấu trúc: Dữ liệu được lưu trữ dưới dạng tệp văn bản hoặc bảng với các yếu tố linh hoạt, như JSON, XML.
- Tích hợp với hệ thống AI: Phù hợp với các ứng dụng cần lưu trữ dữ liệu linh hoạt và có thể thay đổi định dạng theo thời gian.
- Dễ dàng mở rộng và tùy chỉnh: Dữ liệu có thể dễ dàng được mở rộng và thay đổi mà không làm ảnh hưởng đến cấu trúc lưu trữ hiện tại.
- Được sử dụng trong các ứng dụng phân tích dữ liệu lớn: Thường được sử dụng trong các dự án AI liên quan đến việc lưu trữ và phân tích dữ liệu từ nhiều nguồn khác nhau.
3.4. Cơ sở dữ liệu đồ thị
Cơ sở dữ liệu đồ thị (Graph Databases) là loại cơ sở dữ liệu được thiết kế để xử lý dữ liệu dạng đồ thị, nơi các đối tượng được liên kết với nhau qua các mối quan hệ. Đây là lựa chọn lý tưởng cho các ứng dụng AI yêu cầu phân tích mạng lưới kết nối như mạng xã hội, mạng lưới phân phối, hoặc các hệ thống khuyến nghị.
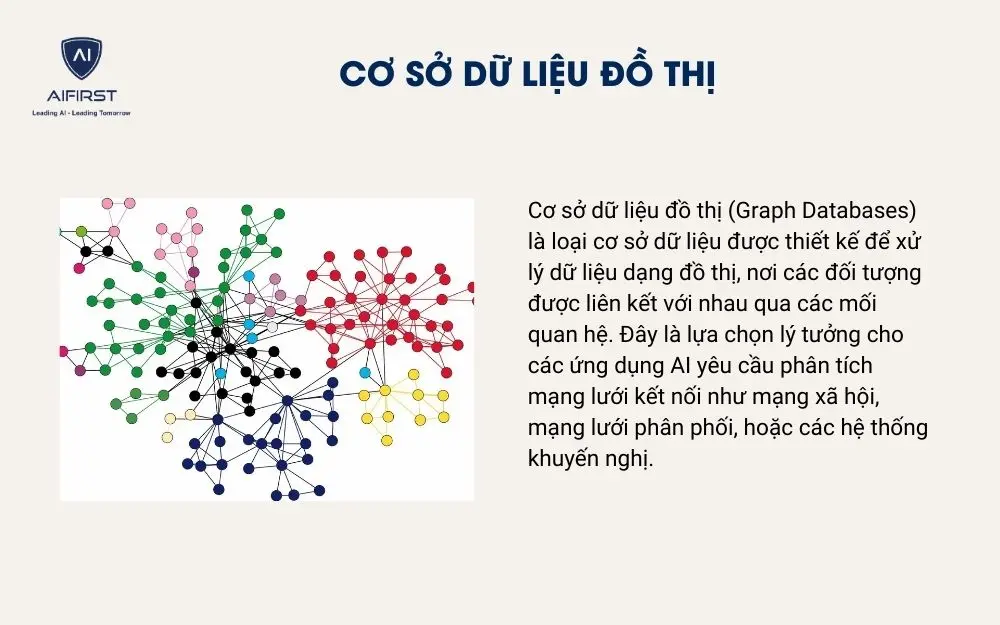
Đặc điểm nổi bật:
- Lưu trữ dữ liệu dạng đồ thị: Dữ liệu được tổ chức dưới dạng các đỉnh (nodes) và các cạnh (edges) để thể hiện các mối quan hệ.
- Tối ưu hóa truy vấn mối quan hệ: Hiệu quả trong việc xử lý các truy vấn liên quan đến các mối quan hệ phức tạp giữa các đối tượng.
- Phân tích mạng lưới và kết nối: Phù hợp cho các ứng dụng như phân tích mạng xã hội, hệ thống khuyến nghị, và tìm kiếm mối quan hệ.
- Ứng dụng trong AI: Dễ dàng tích hợp với các mô hình AI như học máy đồ thị và phân tích mạng lưới.
3.5. Cơ sở dữ liệu in-memory
Cơ sở dữ liệu in-memory (In-Memory Databases) là loại cơ sở dữ liệu lưu trữ dữ liệu trực tiếp trong bộ nhớ (RAM) thay vì trên ổ đĩa. Điều này giúp tăng tốc độ truy cập và xử lý dữ liệu, làm cho nó trở thành sự lựa chọn lý tưởng cho các ứng dụng AI yêu cầu thời gian xử lý cực kỳ nhanh.
Đặc điểm nổi bật:
- Lưu trữ dữ liệu trong bộ nhớ: Tất cả dữ liệu được lưu trữ và truy xuất trực tiếp từ RAM, giúp giảm thiểu độ trễ và tăng tốc độ truy vấn.
- Hiệu suất cao và nhanh chóng: Tối ưu hóa cho các ứng dụng yêu cầu xử lý dữ liệu thời gian thực hoặc gần thời gian thực.
- Giảm tải trên ổ đĩa: Không cần phải đọc/ghi dữ liệu từ ổ đĩa, giúp giảm tải hệ thống và tăng hiệu suất.
- Ứng dụng trong Big Data và AI: Thường được sử dụng trong các ứng dụng yêu cầu phân tích dữ liệu lớn và nhanh, như phân tích thời gian thực và dự báo.
4. Quy trình training AI xây dựng database cho doanh nghiệp
Việc xây dựng một cơ sở dữ liệu cho hệ thống AI là một quy trình quan trọng và phức tạp, đòi hỏi sự chuẩn bị kỹ lưỡng và một chiến lược rõ ràng. Dưới đây là các bước cơ bản trong quy trình training AI để xây dựng và tối ưu hóa cơ sở dữ liệu cho doanh nghiệp, giúp cải thiện hiệu suất, khả năng phân tích dữ liệu và đưa ra quyết định thông minh.

Các bước cơ training AI xây dựng Database
- Bước 1: Xác định mục tiêu và phạm vị
- Bước 2: Thu thập và chuẩn hóa dữ liệu đầu vào
- Bước 3: Quản lý dữ liệu và gắn nhãn tiền xử lý
- Bước 4: Tiến hành từng bước training mô hình AI
- Bước 5: Triển khai và tích hợp vào các hệ thống của doanh nghiệp
- Bước 6: Đánh giá kết quả và bảo trì thường xuyên
Bước 1: Xác định mục tiêu và phạm vị
Trước khi bắt tay vào việc training AI, doanh nghiệp cần xác định rõ mục tiêu của dự án và phạm vi cần xây dựng. Việc này giúp đảm bảo rằng hệ thống AI sẽ phục vụ đúng nhu cầu và giải quyết vấn đề một cách hiệu quả.
- Xác định mục tiêu cụ thể: Doanh nghiệp cần biết rõ mục tiêu mình muốn đạt được từ việc triển khai AI, chẳng hạn như tối ưu hóa quy trình kinh doanh, cải thiện dự báo, hay nâng cao trải nghiệm khách hàng.
- Định rõ phạm vi và yêu cầu: Phạm vi của dự án AI cần phải rõ ràng để xác định các yếu tố cần thu thập và sử dụng trong cơ sở dữ liệu.
- Lên kế hoạch chi tiết: Lên kế hoạch về thời gian, ngân sách và các nguồn lực cần thiết để thực hiện dự án.
Bước 2: Thu thập và chuẩn hóa dữ liệu đầu vào
Dữ liệu là yếu tố quan trọng trong việc huấn luyện AI, vì vậy doanh nghiệp cần thu thập dữ liệu có chất lượng và chuẩn hóa chúng để đảm bảo tính chính xác trong quá trình huấn luyện.

- Thu thập dữ liệu từ nhiều nguồn: Bao gồm dữ liệu từ các hệ thống hiện có, dữ liệu từ khách hàng, dữ liệu thị trường hoặc các nguồn bên ngoài.
- Làm sạch và chuẩn hóa dữ liệu: Xử lý dữ liệu thiếu, sai sót và chuẩn hóa chúng để đảm bảo tính nhất quán và dễ dàng sử dụng trong mô hình AI.
- Đảm bảo tính đầy đủ của dữ liệu: Dữ liệu thu thập cần đủ và phản ánh chính xác các đặc điểm của hệ thống hoặc vấn đề cần giải quyết.
Bước 3: Quản lý dữ liệu và gắn nhãn tiền xử lý
Sau khi thu thập dữ liệu, bước tiếp theo là quản lý và tiền xử lý dữ liệu để chuẩn bị cho quá trình training mô hình AI. Việc này đảm bảo dữ liệu phù hợp và dễ dàng được sử dụng bởi các thuật toán AI.
- Gắn nhãn dữ liệu: Đảm bảo rằng các dữ liệu có nhãn chính xác để mô hình AI có thể học từ chúng (ví dụ: gắn nhãn dữ liệu phân loại).
- Tiền xử lý dữ liệu: Xử lý các dữ liệu như loại bỏ nhiễu, chuẩn hóa các giá trị và tạo ra các đặc trưng quan trọng cho mô hình.
- Quản lý chất lượng dữ liệu: Theo dõi và kiểm soát chất lượng dữ liệu để đảm bảo không có sai sót làm ảnh hưởng đến kết quả của AI.
Bước 4: Tiến hành từng bước training mô hình AI
Bước quan trọng này là quá trình huấn luyện mô hình AI để nó có thể học từ dữ liệu và tạo ra các dự đoán chính xác. Doanh nghiệp cần lựa chọn các thuật toán AI phù hợp với mục tiêu và dữ liệu.
- Chọn mô hình phù hợp: Lựa chọn các mô hình học máy (machine learning), học sâu (deep learning) hoặc các phương pháp AI khác dựa trên dữ liệu và yêu cầu.
- Chạy các thử nghiệm huấn luyện: Tiến hành huấn luyện mô hình trên dữ liệu đã chuẩn bị và tối ưu hóa các tham số để cải thiện hiệu suất.
- Đánh giá và cải tiến mô hình: Đánh giá kết quả mô hình sau mỗi vòng huấn luyện và thực hiện các cải tiến cần thiết để tối ưu hóa độ chính xác.
Bước 5: Triển khai và tích hợp vào các hệ thống của doanh nghiệp
Sau khi huấn luyện xong mô hình AI, doanh nghiệp cần triển khai và tích hợp mô hình vào các hệ thống thực tế để nó có thể hoạt động trong môi trường sản xuất.
- Tích hợp với hệ thống hiện có: Kết nối mô hình AI với các hệ thống của doanh nghiệp như CRM, ERP hoặc các phần mềm quản lý khác.
- Đảm bảo tính tương thích: Đảm bảo rằng mô hình AI có thể tương thích với các công cụ và hệ thống đang hoạt động trong doanh nghiệp.
- Theo dõi hiệu suất sau khi triển khai: Giám sát và đo lường hiệu suất của mô hình AI sau khi tích hợp vào hệ thống thực tế.
Bước 6: Đánh giá kết quả và bảo trì thường xuyên
Cuối cùng, sau khi mô hình AI được triển khai, doanh nghiệp cần đánh giá kết quả và thực hiện bảo trì thường xuyên để đảm bảo rằng mô hình luôn đạt hiệu quả tối ưu.

- Đánh giá hiệu suất: So sánh kết quả thực tế với các mục tiêu đã xác định ở bước đầu để xem mô hình AI có hoạt động như kỳ vọng không.
- Bảo trì và cập nhật mô hình: Thường xuyên cập nhật mô hình với dữ liệu mới và cải thiện hiệu suất để phản ánh sự thay đổi trong môi trường kinh doanh.
- Thu thập phản hồi và tối ưu hóa: Thu thập phản hồi từ người dùng và tối ưu hóa mô hình để đáp ứng tốt hơn nhu cầu và yêu cầu của doanh nghiệp.
5. Các trường hợp cần sử dụng cơ sở dữ liệu AI
Cơ sở dữ liệu AI đóng vai trò quan trọng trong việc hỗ trợ và cải thiện các ứng dụng trí tuệ nhân tạo (AI) trong nhiều lĩnh vực khác nhau. Các công nghệ AI như học máy và xử lý ngôn ngữ tự nhiên phụ thuộc vào các cơ sở dữ liệu để phân tích và lưu trữ thông tin hiệu quả.
- Phát hiện đối tượng và phân tích văn bản: Một trong những ứng dụng nổi bật của AI databases là phát hiện đối tượng và phân tích văn bản. Các cơ sở dữ liệu này hỗ trợ nhận diện và phân tích dữ liệu hình ảnh, văn bản từ các tài liệu và giao tiếp, giúp các mô hình AI nhanh chóng rút ra thông tin quan trọng.
- Nhận dạng giọng nói: Cơ sở dữ liệu AI hỗ trợ các hệ thống nhận dạng giọng nói, giúp chuyển đổi lời nói thành văn bản, hỗ trợ các ứng dụng như trợ lý ảo, dịch vụ chăm sóc khách hàng tự động và các hệ thống tìm kiếm bằng giọng nói.
- Lọc mạng xã hội: AI có thể giúp lọc và phân tích dữ liệu từ các nền tảng mạng xã hội như Facebook, Twitter, hoặc Instagram. Cơ sở dữ liệu AI hỗ trợ doanh nghiệp trong việc phân tích cảm xúc, xu hướng, và các mẫu hành vi người dùng.
- Kiểm tra bằng mắt thường: Cơ sở dữ liệu AI hỗ trợ kiểm tra bằng mắt thường trong các lĩnh vực như sản xuất và kiểm soát chất lượng. AI có thể nhận diện các lỗi hoặc sự bất thường trong sản phẩm mà con người có thể bỏ sót.
- Xử lý ngôn ngữ tự nhiên: Xử lý ngôn ngữ tự nhiên (NLP) là một trong những ứng dụng chính của AI databases. Các cơ sở dữ liệu AI giúp xử lý và phân tích dữ liệu ngôn ngữ tự nhiên, cải thiện khả năng giao tiếp giữa máy và người.
6. Những công cụ chính hỗ trợ triển khai cơ sở dữ liệu AI
Để xây dựng và quản lý cơ sở dữ liệu AI hiệu quả, doanh nghiệp cần sử dụng các công cụ mạnh mẽ giúp thu thập, xử lý và phân tích dữ liệu lớn. Các công cụ này không chỉ tối ưu hóa quy trình lưu trữ mà còn giúp tích hợp và huấn luyện mô hình AI một cách hiệu quả.
Những công cụ chính hỗ trợ triển khai cơ sở dữ liệu AI:
- Apache Kafka: Là nền tảng xử lý luồng dữ liệu mã nguồn mở, cho phép thu thập và xử lý dữ liệu theo thời gian thực. Với khả năng mở rộng cao, Kafka có thể xử lý hàng triệu sự kiện mỗi giây và dễ dàng tích hợp với các công cụ AI khác.
- TensorFlow Data: Là thư viện giúp tối ưu hóa việc tải và xử lý dữ liệu lớn trong các mô hình học máy, hỗ trợ cải thiện hiệu suất huấn luyện mô hình và có khả năng xử lý nhiều loại định dạng dữ liệu.
- Apache HBase: Là cơ sở dữ liệu phân tán không quan hệ, được thiết kế để xử lý và lưu trữ dữ liệu lớn, có khả năng mở rộng linh hoạt và lưu trữ dữ liệu không có cấu trúc như văn bản hoặc hình ảnh.
- SpaCy: Là một thư viện mã nguồn mở mạnh mẽ trong xử lý ngôn ngữ tự nhiên (NLP), giúp phân tích và hiểu ngữ nghĩa văn bản một cách chính xác và nhanh chóng.
- PyTorch: Là thư viện học sâu mã nguồn mở được sử dụng rộng rãi trong nghiên cứu và phát triển mô hình AI. PyTorch hỗ trợ tính toán trên GPU để tăng tốc quá trình huấn luyện, cho phép xây dựng các mô hình học sâu phức tạp và dễ dàng tích hợp với các công cụ AI khác.
- MLflow: Là nền tảng mã nguồn mở giúp quản lý toàn bộ vòng đời của mô hình học máy, từ huấn luyện đến triển khai và theo dõi hiệu suất.
6.1. Apache Kafka
Apache Kafka là một nền tảng xử lý luồng dữ liệu mã nguồn mở, giúp doanh nghiệp thu thập và xử lý dữ liệu theo thời gian thực. Nó được sử dụng để xây dựng hệ thống dữ liệu phân tán, có khả năng mở rộng linh hoạt và xử lý lượng dữ liệu lớn một cách hiệu quả.
- Xử lý dữ liệu theo thời gian thực: Kafka cho phép thu thập và phân tích dữ liệu ngay khi dữ liệu được tạo ra.
- Khả năng mở rộng cao: Có thể xử lý hàng triệu sự kiện mỗi giây mà không làm giảm hiệu suất hệ thống.
- Quản lý luồng dữ liệu phân tán: Cho phép doanh nghiệp quản lý và xử lý dữ liệu phân tán dễ dàng trên các hệ thống khác nhau.
- Tích hợp dễ dàng với các hệ thống khác: Kafka dễ dàng tích hợp với các công cụ và ứng dụng AI khác như Apache Spark hoặc TensorFlow.
6.2. TensorFlow Data
TensorFlow Data là một thư viện trong TensorFlow giúp tối ưu hóa việc tải và xử lý dữ liệu lớn cho các mô hình học máy. Nó hỗ trợ doanh nghiệp trong việc quản lý dữ liệu, từ việc tải dữ liệu cho đến việc chuẩn bị và phân phối dữ liệu cho quá trình huấn luyện AI.

- Xử lý dữ liệu lớn: TensorFlow Data hỗ trợ việc xử lý và tải dữ liệu từ các nguồn lớn và phức tạp như hình ảnh, video và văn bản.
- Tích hợp với TensorFlow: Dễ dàng tích hợp với TensorFlow, giúp tối ưu hóa quá trình huấn luyện mô hình AI.
- Cải thiện hiệu suất và tốc độ huấn luyện: Cho phép dữ liệu được chuẩn bị và phân phối hiệu quả, giúp tăng tốc quá trình huấn luyện.
- Hỗ trợ nhiều định dạng dữ liệu: Có thể xử lý dữ liệu từ các định dạng khác nhau như CSV, JSON, và hình ảnh.
6.3. Apache HBase
Apache HBase là một cơ sở dữ liệu phân tán và không quan hệ, được thiết kế để xử lý dữ liệu lớn trong môi trường yêu cầu tính sẵn sàng cao và khả năng mở rộng. HBase là lựa chọn lý tưởng cho các ứng dụng AI cần lưu trữ và truy xuất dữ liệu nhanh chóng và hiệu quả.
- Xử lý dữ liệu lớn: Phù hợp cho các doanh nghiệp cần lưu trữ và xử lý khối lượng dữ liệu khổng lồ.
- Khả năng mở rộng ngang: Có thể dễ dàng mở rộng khi yêu cầu lưu trữ hoặc xử lý dữ liệu tăng cao.
- Lưu trữ dữ liệu không có cấu trúc: HBase hỗ trợ lưu trữ dữ liệu phi cấu trúc như văn bản và hình ảnh.
- Tính sẵn sàng cao: Đảm bảo rằng hệ thống vẫn hoạt động liên tục, ngay cả khi có sự cố phần cứng.
6.4. SpaCy
SpaCy là một thư viện mã nguồn mở mạnh mẽ trong xử lý ngôn ngữ tự nhiên (NLP). Được thiết kế để xử lý và phân tích văn bản nhanh chóng và hiệu quả, SpaCy là một công cụ lý tưởng cho các ứng dụng AI cần phân tích và hiểu ngữ nghĩa trong văn bản.
- Xử lý ngôn ngữ tự nhiên: SpaCy giúp phân tích và hiểu ngữ nghĩa của văn bản một cách chính xác.
- Tích hợp mô hình học sâu: Hỗ trợ các mô hình học sâu để thực hiện các nhiệm vụ NLP như phân loại văn bản và phân tích cảm xúc.
- Hiệu suất cao và nhanh chóng: SpaCy được tối ưu hóa để xử lý dữ liệu ngôn ngữ tự nhiên với tốc độ và hiệu quả cao.
- Hỗ trợ nhiều ngôn ngữ: SpaCy có thể xử lý dữ liệu văn bản từ nhiều ngôn ngữ khác nhau, làm cho nó phù hợp với các ứng dụng toàn cầu.
6.5. PyTorch
PyTorch là một thư viện học sâu mã nguồn mở, được sử dụng rộng rãi trong nghiên cứu và phát triển mô hình AI. PyTorch cung cấp các công cụ mạnh mẽ để xây dựng, huấn luyện và triển khai các mô hình học sâu, từ các mô hình mạng nơ-ron đơn giản đến các mô hình phức tạp.

- Dễ sử dụng và linh hoạt: PyTorch cung cấp một API dễ sử dụng và linh hoạt cho việc xây dựng mô hình học sâu.
- Hỗ trợ tính toán trên GPU: Tăng tốc quá trình huấn luyện và phân tích với khả năng xử lý tính toán trên GPU.
- Hỗ trợ đào tạo mô hình phức tạp: Cho phép xây dựng các mô hình học sâu phức tạp cho các ứng dụng AI tiên tiến.
- Cộng đồng phát triển mạnh mẽ: PyTorch có một cộng đồng phát triển lớn và liên tục cải tiến, hỗ trợ người dùng trong việc triển khai và tối ưu hóa mô hình AI.
6.6. MLflow
MLflow là một nền tảng mã nguồn mở giúp quản lý toàn bộ vòng đời của mô hình học máy. Từ việc huấn luyện và thử nghiệm mô hình đến triển khai và theo dõi hiệu suất, MLflow giúp doanh nghiệp quản lý quá trình phát triển AI một cách dễ dàng.
- Quản lý mô hình học máy: MLflow giúp theo dõi, quản lý và triển khai các mô hình học máy trong suốt vòng đời phát triển.
- Hỗ trợ thử nghiệm mô hình: Cho phép doanh nghiệp thử nghiệm nhiều mô hình khác nhau và theo dõi kết quả.
- Dễ dàng tích hợp: MLflow có thể dễ dàng tích hợp với các công cụ và thư viện học máy khác, bao gồm TensorFlow và PyTorch.
- Quản lý dữ liệu và môi trường: Hỗ trợ quản lý các phiên làm việc, môi trường và dữ liệu sử dụng trong các mô hình.
Với sự phát triển mạnh mẽ của công nghệ AI, việc sử dụng AI Databases ngày càng trở nên quan trọng đối với doanh nghiệp. Các cơ sở dữ liệu AI không chỉ giúp lưu trữ và quản lý dữ liệu một cách hiệu quả mà còn hỗ trợ việc huấn luyện và triển khai các mô hình AI một cách tối ưu. Qua bài viết trên, AI First mong rằng sẽ giúp doanh nghiệp khai thác và phát huy tối đa giá trị của dữ liệu, từ đó nâng cao hiệu suất và khả năng cạnh tranh trong thị trường hiện đại.




