Mục lục [Ẩn]
Trong kỷ nguyên số, dữ liệu là “tài sản sống” của mọi doanh nghiệp. Tuy nhiên, dữ liệu sai sót, trùng lặp, thiếu nhất quán lại đang âm thầm làm suy yếu các chiến lược marketing, chăm sóc khách hàng. Vậy làm sạch dữ liệu là gì, quy trình triển khai như thế nào, và AI có thể hỗ trợ xử lý dữ liệu ra sao? Bài viết dưới đây cùng AI First tìm hiểu về làm sạch dữ liệu, cách ứng dụng AI thực tiễn giúp doanh nghiệp sẵn sàng tăng tốc trong hành trình chuyển đổi số.
1. Làm sạch dữ liệu (Data Cleaning) là gì?
Làm sạch dữ liệu (Data Cleaning hay Data Cleansing) là quá trình phát hiện, sửa chữa hoặc loại bỏ dữ liệu bị sai, trùng lặp, thiếu hoặc không nhất quán trong một tập dữ liệu. Đây là bước quan trọng để đảm bảo dữ liệu được sử dụng trong phân tích, báo cáo, hoặc huấn luyện AI/ML là chính xác, đầy đủ và đáng tin cậy.

Trong lĩnh vực phân tích dữ liệu và trí tuệ nhân tạo, làm sạch dữ liệu đóng vai trò như bước “lọc rác”. Nếu dữ liệu đầu vào không chuẩn, mọi kết quả phân tích hay dự báo đều dễ sai lệch. Chính vì vậy, Data Cleaning được xem là nền tảng của mọi dự án chuyển đổi số và AI.
2. Lợi ích của việc làm sạch dữ liệu
Việc làm sạch dữ liệu (data cleaning) không chỉ là bước khởi đầu trong quá trình xử lý dữ liệu, mà còn là yếu tố sống còn giúp doanh nghiệp tối ưu hiệu quả vận hành, khai thác dữ liệu chính xác và triển khai công nghệ AI hiệu quả. Dưới đây là những lợi ích nổi bật của việc làm sạch dữ liệu đối với doanh nghiệp hiện đại.

- Nâng cao độ chính xác trong phân tích và ra quyết định: Dữ liệu sạch giúp loại bỏ sai lệch, trùng lặp, lỗi nhập liệu và các điểm bất thường, từ đó đảm bảo kết quả phân tích chính xác, hỗ trợ nhà lãnh đạo đưa ra quyết định đúng đắn và kịp thời.
- Tiết kiệm chi phí và thời gian xử lý: Việc loại bỏ dữ liệu không hợp lệ ngay từ đầu giúp tiết kiệm đáng kể thời gian xử lý thủ công, giảm chi phí liên quan đến việc chỉnh sửa, làm lại hoặc xử lý lỗi phát sinh từ dữ liệu bẩn.
- Gia tăng hiệu quả ứng dụng AI, Big Data, Machine Learning: Các mô hình AI và thuật toán học máy hoạt động hiệu quả hơn khi được "nuôi" bằng dữ liệu sạch, từ đó cải thiện độ chính xác dự báo và khả năng tự động hóa các quy trình kinh doanh.
- Tăng cường hiệu suất marketing, bán hàng và chăm sóc khách hàng: Dữ liệu khách hàng được làm sạch giúp cá nhân hóa chiến dịch marketing, tăng khả năng chuyển đổi trong bán hàng và cung cấp dịch vụ chăm sóc khách hàng nhanh chóng, chính xác hơn.
- Tăng sự tuân thủ và bảo mật dữ liệu: Việc duy trì dữ liệu sạch giúp doanh nghiệp tuân thủ các quy định về quản lý dữ liệu (như GDPR), đồng thời giảm thiểu rủi ro rò rỉ thông tin do lưu trữ dữ liệu sai lệch, lỗi thời hoặc không được phân quyền đúng cách.
3. Nguyên nhân của các vấn đề về chất lượng dữ liệu
Chất lượng dữ liệu thấp là một trong những rào cản lớn nhất khiến các doanh nghiệp không thể tận dụng tối đa tiềm năng của công nghệ AI, Big Data hay các hệ thống quản trị. Dưới đây là những nguyên nhân phổ biến nhất dẫn đến vấn đề về chất lượng dữ liệu mà các doanh nghiệp SMEs cần đặc biệt lưu ý.
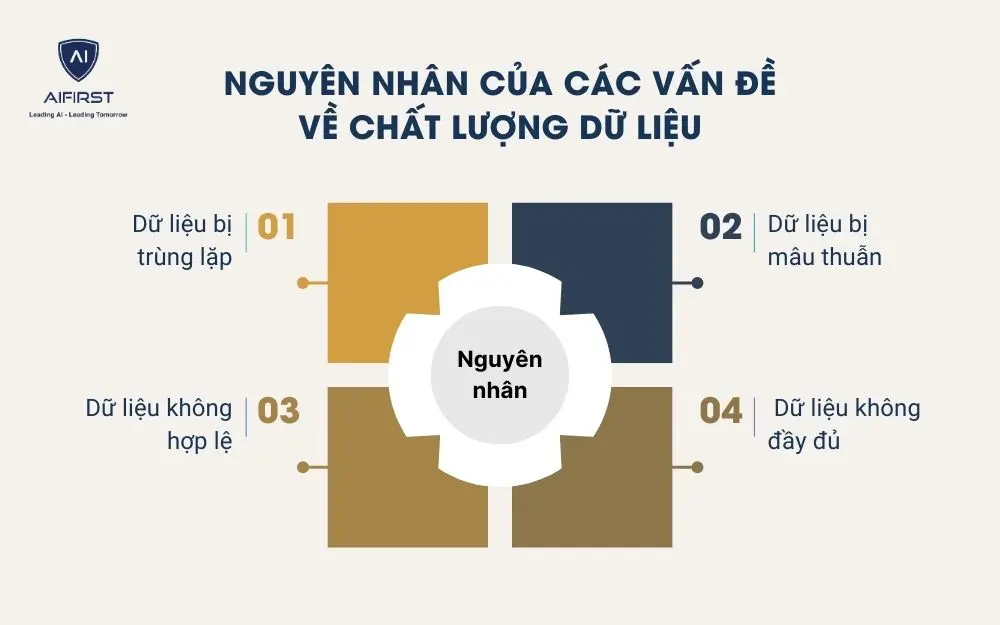
3.1. Dữ liệu bị trùng lặp
Dữ liệu bị trùng lặp là một trong những “căn bệnh mãn tính” của nhiều hệ thống quản lý dữ liệu trong doanh nghiệp. Tình trạng này thường xảy ra khi cùng một khách hàng, sản phẩm hoặc giao dịch được ghi lại nhiều lần với các biến thể khác nhau, gây rối loạn nghiêm trọng trong phân tích và báo cáo. Hậu quả là doanh nghiệp không thể xác định được đâu là dữ liệu chuẩn, dẫn đến việc đánh giá sai số lượng khách hàng thực tế, báo cáo tài chính không chính xác, và các chiến dịch marketing bị kém hiệu quả do gửi trùng lặp nhiều lần.
Một số nguyên nhân gây ra dữ liệu trùng lặp bao gồm:
- Không có quy chuẩn định danh dữ liệu: Thiếu mã ID duy nhất cho mỗi khách hàng hoặc giao dịch khiến hệ thống không thể phân biệt được bản ghi đã tồn tại.
- Nhập liệu thủ công từ nhiều nguồn khác nhau: Khi dữ liệu được thu thập từ email, telesale, landing page, hội thảo, v.v… mà không có hệ thống đồng bộ, trùng lặp gần như là điều không tránh khỏi.
- Tích hợp hệ thống không đồng bộ: Các phần mềm hệ thống CRM, hệ thống ERP, POS hoạt động độc lập mà không có liên kết chuẩn hóa, gây ra nhiều phiên bản dữ liệu giống nhau ở nhiều nơi.
3.2. Dữ liệu bị mâu thuẫn
Dữ liệu mâu thuẫn là tình trạng cùng một thông tin nhưng lại có nhiều phiên bản khác nhau, khiến doanh nghiệp không thể xác định đâu là dữ liệu đúng. Đây là nguyên nhân chính dẫn đến sự thiếu nhất quán trong báo cáo, khiến CEO hoặc quản lý ra quyết định dựa trên nền tảng thông tin không chính xác.

Một số nguyên nhân gây ra dữ liệu bị mâu thuẫn bao gồm:
- Thiếu chuẩn hóa dữ liệu đầu vào: Các trường thông tin không được cố định định dạng, ví dụ một địa chỉ có thể được nhập dưới nhiều cách viết khác nhau: “TP.HCM”, “HCM”, “Hồ Chí Minh”.
- Thiết lập quyền chỉnh sửa không rõ ràng: Khi nhiều người cùng sửa dữ liệu mà không kiểm soát được lịch sử chỉnh sửa, dễ dẫn đến sai lệch và nhầm lẫn.
- Không có cơ chế đối soát dữ liệu giữa các phòng ban: Dữ liệu bị cập nhật độc lập tại từng bộ phận (bán hàng, marketing, CSKH...) mà không được hợp nhất hoặc đối chiếu.
3.3. Dữ liệu không hợp lệ
Dữ liệu không hợp lệ là những thông tin không đúng định dạng, sai logic hoặc không tuân thủ quy định hệ thống. Đây là loại dữ liệu rất nguy hiểm vì không chỉ gây lỗi trong vận hành mà còn ảnh hưởng đến độ tin cậy của toàn bộ hệ thống phân tích. Ví dụ: một số điện thoại thiếu ký tự, một email không có dấu “@” vẫn được lưu lại hệ thống khiến việc liên lạc hoặc tự động hóa chăm sóc khách hàng gặp sai sót nghiêm trọng.
Một số nguyên nhân khiến dữ liệu không hợp lệ:
- Thiếu công cụ xác minh định dạng dữ liệu: Không có validation (ràng buộc kỹ thuật) khiến hệ thống chấp nhận thông tin sai một cách dễ dãi.
- Form biểu mẫu được thiết kế sơ sài: Không bắt buộc nhập đúng định dạng, không báo lỗi hoặc không yêu cầu đầy đủ trường bắt buộc.
- Lỗi trong quá trình chuyển đổi giữa các hệ thống: Dữ liệu khi di chuyển từ phần mềm A sang phần mềm B bị biến dạng do không tương thích cấu trúc.
3.4. Dữ liệu không đầy đủ
Một trong những nguyên nhân âm thầm nhưng nguy hiểm nhất là dữ liệu không đầy đủ. Doanh nghiệp sở hữu hàng nghìn bản ghi khách hàng, nhưng lại thiếu các trường thông tin quan trọng như số điện thoại, email, hành vi mua hàng, lịch sử tương tác,... Điều này khiến việc cá nhân hóa marketing, chăm sóc khách hàng hoặc dự báo xu hướng trở nên bất khả thi.

Một số nguyên nhân dẫn đến tình trạng dữ liệu thiếu hụt:
- Người dùng bỏ qua các trường quan trọng: Form đăng ký không thiết kế hấp dẫn, không yêu cầu bắt buộc nhập đầy đủ khiến người dùng chỉ điền thông tin sơ sài.
- Doanh nghiệp không có quy trình cập nhật định kỳ: Sau khi thu thập dữ liệu ban đầu, không có bộ phận chịu trách nhiệm hoàn thiện hoặc bổ sung thêm thông tin.
- Hệ thống lưu trữ dữ liệu phân tán: Dữ liệu nằm rải rác ở nhiều nền tảng (Google Sheet, phần mềm CRM, Excel offline,...) khiến việc tổng hợp đầy đủ trở nên rất khó khăn.
4. Làm sạch dữ liệu giúp triển khai marketing hiệu quả hơn như thế nào?
Trong môi trường marketing hiện đại, nơi dữ liệu quyết định hiệu quả của gần như mọi chiến dịch thì việc sở hữu nguồn dữ liệu chính xác, đầy đủ và cập nhật trở thành lợi thế cạnh tranh của doanh nghiệp. Làm sạch dữ liệu không chỉ giúp doanh nghiệp hiểu đúng về khách hàng, mà còn đảm bảo các công cụ AI, CDP, CRM, hệ thống marketing automation vận hành trơn tru, cá nhân hóa hiệu quả và tối ưu chi phí.
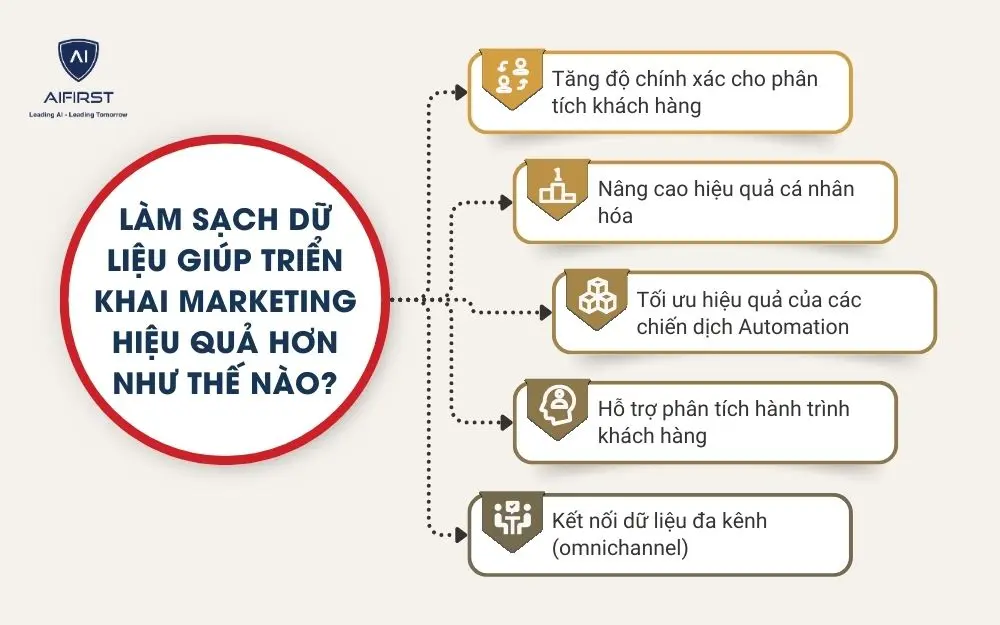
4.1. Tăng độ chính xác cho phân tích khách hàng
Phân tích khách hàng là nền tảng cho mọi chiến lược marketing. Nếu dữ liệu sai lệch, doanh nghiệp sẽ vẽ sai chân dung khách hàng, dẫn đến định vị sai sản phẩm, quảng cáo sai đối tượng, hoặc truyền thông sai thông điệp. Khi dữ liệu được làm sạch loại bỏ trùng lặp, lỗi nhập liệu và thiếu nhất quán, các công cụ phân tích như Google Analytics, CRM hay BI dashboard mới có thể đưa ra báo cáo đáng tin cậy. Điều này giúp CEO, CMO và đội ngũ marketing đưa ra các quyết định chiến lược đúng đắn hơn.
- Phân loại khách hàng chính xác: Nhóm khách hàng được phân chia đúng theo độ tuổi, khu vực, hành vi tiêu dùng, tăng khả năng nhắm trúng mục tiêu trong chiến dịch.
- Hiểu đúng insight người dùng: Giúp doanh nghiệp tránh nhận định sai lệch do dữ liệu lỗi hoặc không đồng nhất giữa các kênh.
- Phân tích hiệu suất chiến dịch thực tế: Dữ liệu sạch giúp đánh giá hiệu quả thực sự của từng kênh và chiến lược đã triển khai.
4.2. Nâng cao hiệu quả cá nhân hóa
Cá nhân hóa là chìa khóa để thu hút và giữ chân khách hàng trong môi trường cạnh tranh hiện nay. Tuy nhiên, cá nhân hóa chỉ phát huy sức mạnh khi dữ liệu đầu vào đầy đủ và chính xác. Một email chào mời sai tên, một quảng cáo retargeting không liên quan, hoặc một đề xuất sản phẩm "lạc quẻ" đều có thể khiến khách hàng cảm thấy bị làm phiền và mất niềm tin. Làm sạch dữ liệu chính là điều kiện tiên quyết để xây dựng trải nghiệm khách hàng mang tính cá nhân hóa thật sự.

- Thông tin khách hàng đúng & đầy đủ: Đảm bảo tên, giới tính, hành vi, lịch sử mua hàng,... không bị sai hoặc thiếu sót.
- Gửi thông điệp đúng người, đúng thời điểm: Giúp hệ thống marketing automation đưa ra kịch bản phù hợp theo từng hành vi cụ thể.
- Tăng tỷ lệ phản hồi: Khi khách hàng cảm thấy nội dung phù hợp với nhu cầu của mình, tỷ lệ mở, click và chuyển đổi sẽ cao hơn rõ rệt.
4.3. Tối ưu hiệu quả của các chiến dịch Automation
Marketing automation giúp tiết kiệm thời gian, tăng độ chính xác và tạo quy trình chăm sóc khách hàng mượt mà. Tuy nhiên, nếu dữ liệu đầu vào sai lệch, hệ thống automation sẽ hoạt động sai logic, làm ảnh hưởng nghiêm trọng đến trải nghiệm người dùng. Làm sạch dữ liệu giúp hệ thống phân luồng khách hàng đúng hành trình, tránh spam và tối ưu hiệu suất tự động hóa.
- Tránh gửi trùng, sai nội dung: Dữ liệu sạch đảm bảo mỗi khách hàng chỉ nhận đúng nội dung dành cho họ, không bị gửi đi gửi lại hoặc rơi vào kịch bản sai.
- Phân luồng hành trình chính xác: Tự động hóa chăm sóc theo từng giai đoạn mua hàng chỉ hoạt động hiệu quả khi dữ liệu khách hàng rõ ràng, không trùng lặp.
- Tối ưu nguồn lực đội ngũ: Giảm sự can thiệp thủ công và sửa lỗi trong các chiến dịch automation phức tạp.
4.4. Hỗ trợ phân tích hành trình khách hàng
Hành trình khách hàng (customer journey) ngày nay không còn tuyến tính mà trải dài qua nhiều kênh, nhiều giai đoạn. Doanh nghiệp cần biết chính xác khách hàng tương tác từ đâu, phản hồi lúc nào, đang ở giai đoạn nào trong phễu mua hàng để ra quyết định kịp thời. Nếu dữ liệu không được làm sạch, doanh nghiệp sẽ vẽ sai hành trình này, dẫn đến truyền thông lệch pha và chăm sóc không phù hợp.
- Truy vết chính xác điểm chạm: Nhận diện khách hàng từng truy cập từ Google Ads, Zalo OA, website hay chatbot mà không nhầm lẫn giữa các phiên bản dữ liệu.
- Tối ưu từng bước trong phễu bán hàng: Hiểu rõ hành vi ở mỗi giai đoạn giúp thiết kế nội dung phù hợp, tăng tỷ lệ chuyển đổi từng bước.
- Hạn chế rò rỉ khách hàng: Biết được nguyên nhân khách hàng rơi rụng ở bước nào để kịp thời điều chỉnh.
4.5. Kết nối dữ liệu đa kênh (omnichannel)
Trong kỷ nguyên Omnichannel, khách hàng tương tác với doanh nghiệp qua nhiều điểm chạm khác nhau: Facebook, Zalo, website, email, cửa hàng, hotline… Nếu dữ liệu không được đồng bộ và làm sạch, trải nghiệm khách hàng sẽ bị đứt gãy, thông tin không khớp giữa các kênh và doanh nghiệp mất cơ hội bán hàng. Làm sạch dữ liệu giúp gom toàn bộ dữ liệu từ nhiều nguồn vào một trung tâm (CDP hoặc CRM), từ đó triển khai chiến lược omnichannel marketing hiệu quả hơn.

- Tránh trùng lặp dữ liệu giữa các nền tảng: Đảm bảo mỗi khách hàng chỉ có một hồ sơ duy nhất, dù họ tương tác ở bất kỳ đâu.
- Tạo trải nghiệm cá nhân hóa liền mạch: Dữ liệu đồng bộ giúp cá nhân hóa thông điệp xuyên suốt từ online đến offline.
- Tăng sự hài lòng và trung thành: Khách hàng cảm thấy được thấu hiểu và chăm sóc tốt hơn, dù ở bất kỳ kênh nào.
5. Những tiêu chí của một dữ liệu đạt chuẩn
Để triển khai thành công các hoạt động liên quan đến marketing, bán hàng, chăm sóc khách hàng hay ứng dụng AI, dữ liệu không chỉ cần "sạch", mà còn phải đạt chuẩn theo các tiêu chí quan trọng. Dưới đây là 7 tiêu chí quan trọng giúp doanh nghiệp đánh giá và duy trì chất lượng dữ liệu ở mức cao nhất.

5.1. Tính chuẩn xác
Tính chuẩn xác thể hiện việc dữ liệu có đúng với định dạng và quy chuẩn kỹ thuật không. Đây là bước đầu tiên để đảm bảo dữ liệu không bị lỗi định dạng, sai kiểu dữ liệu hoặc nhập sai cấu trúc khiến hệ thống xử lý bị gián đoạn.
- Dữ liệu tuân thủ đúng quy chuẩn định dạng: Ví dụ: email phải có ký hiệu "@", số điện thoại có đúng độ dài và bắt đầu bằng đầu số hợp lệ.
- Được kiểm soát thông qua validation form: Các biểu mẫu đầu vào phải có công cụ kiểm tra định dạng để đảm bảo chỉ dữ liệu chuẩn mới được lưu vào hệ thống.
- Tránh lỗi kỹ thuật trong quá trình chuyển đổi hệ thống: Định dạng dữ liệu được giữ nguyên khi di chuyển giữa các phần mềm, API hoặc hệ quản trị dữ liệu.
5.2. Tính chính xác
Tính chính xác đảm bảo rằng dữ liệu phản ánh đúng thực tế. Đây là yếu tố then chốt để dữ liệu có thể dùng trong phân tích, báo cáo và ra quyết định. Dữ liệu không chính xác dẫn đến sai lệch trong nhận định và gây thiệt hại cho doanh nghiệp.

- Phản ánh đúng thông tin thực tế: Ví dụ: địa chỉ khách hàng đúng vị trí thực tế, sản phẩm có giá chính xác tại thời điểm giao dịch.
- Không bị sai lệch do lỗi nhập liệu hoặc hệ thống: Tránh các trường hợp đánh máy nhầm số liệu, sai ngày tháng, nhầm mã đơn hàng,...
- Cập nhật đúng nguồn và đáng tin cậy: Dữ liệu được thu thập từ các nguồn chính thống, có xác thực rõ ràng.
5.3. Tính đầy đủ
Dữ liệu đầy đủ là khi mọi thông tin cần thiết cho quá trình phân tích, dự báo hoặc tự động hóa đều đã có mặt trong hệ thống. Dữ liệu thiếu sót sẽ làm giảm giá trị khai thác và không thể tạo nên bức tranh toàn diện về khách hàng hay hoạt động kinh doanh.
- Tất cả trường thông tin quan trọng đều được điền: Các trường thông tin quan trọng như: họ tên, email, số điện thoại, khu vực, lịch sử mua hàng,... đều cần được điền đầy đủ.
- Không để trống các trường bắt buộc: Thiết kế biểu mẫu đầu vào phải đảm bảo khách hàng hoặc nhân viên không bỏ sót các thông tin thiết yếu.
- Được cập nhật liên tục theo thời gian: Dữ liệu luôn được hoàn thiện và bổ sung khi có thay đổi hoặc phát sinh mới.
5.4. Tính nhất quán
Tính nhất quán đảm bảo dữ liệu không bị mâu thuẫn giữa các hệ thống hoặc các trường thông tin. Một khách hàng chỉ nên có một phiên bản thông tin chính xác được đồng bộ giữa các nền tảng. Dữ liệu thiếu nhất quán gây rối loạn nghiêm trọng trong báo cáo và phân tích.

- Giữ đồng bộ giữa các hệ thống ERP, CRM, CDP,...: Giúp việc đồng bộ các hệ thống ERP, CRM và CDP trở nên dễ dàng hơn. Ví dụ, nếu khách hàng thay đổi email trong CRM thì thông tin đó cũng được cập nhật ở hệ thống chăm sóc khách hàng.
- Không có xung đột giữa các bản ghi: Tránh tình trạng một khách hàng có nhiều bản ghi với thông tin khác nhau.
- Có quy trình kiểm tra và rà soát định kỳ: Tự động phát hiện và báo lỗi khi phát sinh dữ liệu mâu thuẫn giữa các hệ thống.
5.5. Tính đồng nhất
Đây là tiêu chí thể hiện sự thống nhất về cách trình bày dữ liệu. Ví dụ: tất cả ngày tháng nên theo một định dạng, đơn vị đo lường nên được chuẩn hóa,… Đồng nhất giúp dễ dàng phân tích, đối chiếu và xử lý trên quy mô lớn.
- Chuẩn hóa định dạng trên toàn hệ thống: Ví dụ: ngày sinh theo định dạng DD/MM/YYYY, đơn vị tiền tệ là VND, ký hiệu viết hoa đúng quy ước.
- Loại bỏ cách viết không đồng bộ: Tránh nhập một trường thông tin theo nhiều cách viết khác nhau (VD: “TP.HCM” vs “Hồ Chí Minh” vs “HCM”).
- Giúp dữ liệu dễ tích hợp vào báo cáo hoặc phân tích AI: Khi dữ liệu đồng nhất, hệ thống sẽ xử lý nhanh và giảm lỗi trong các mô hình phân tích.
5.6. Tính minh bạch
Dữ liệu minh bạch nghĩa là doanh nghiệp biết rõ nguồn gốc, cách thức thu thập và chỉnh sửa dữ liệu. Điều này rất quan trọng trong việc quản trị rủi ro, bảo vệ quyền riêng tư và tuân thủ quy định pháp lý như GDPR.

- Xác định được nguồn dữ liệu: Có thể truy vết được dữ liệu thu từ đâu (form đăng ký, telesales, hệ thống CRM,...).
- Có lịch sử chỉnh sửa rõ ràng: Mỗi lần dữ liệu được cập nhật đều có ghi nhận ai cập nhật, khi nào và vì lý do gì.
- Phù hợp với quy định bảo mật và quyền riêng tư: Đảm bảo quyền truy cập, chỉnh sửa và xóa dữ liệu được phân quyền đúng người.
5.7. Tính kịp thời
Tính kịp thời là khả năng cập nhật dữ liệu một cách nhanh chóng và phù hợp với thời điểm thực tế. Dữ liệu lỗi thời sẽ khiến chiến dịch marketing trở nên vô nghĩa và sai đối tượng. Đây là yếu tố đặc biệt quan trọng trong môi trường cạnh tranh nhanh như hiện nay.
- Dữ liệu luôn được cập nhật thời gian thực hoặc định kỳ: Đảm bảo phản ánh đúng hành vi, trạng thái mới nhất của khách hàng.
- Loại bỏ hoặc cập nhật dữ liệu cũ: Những dữ liệu không còn sử dụng được cần được loại khỏi hệ thống hoặc gắn nhãn "hết hạn".
- Đáp ứng yêu cầu phân tích và hành động tức thì: Giúp hệ thống automation, chatbot AI, CDP phản ứng nhanh theo hành vi người dùng.
6. Quy trình ứng dụng AI làm sạch dữ liệu
Để dữ liệu thực sự “sạch” và sẵn sàng sử dụng trong marketing, bán hàng, chăm sóc khách hàng hoặc phân tích kinh doanh, các doanh nghiệp không thể chỉ dựa vào thao tác thủ công. Thay vào đó, ứng dụng AI vào quy trình làm sạch dữ liệu đang trở thành giải pháp chiến lược, giúp tiết kiệm thời gian, tăng độ chính xác và đảm bảo tính cập nhật liên tục.
Dưới đây là quy trình 6 bước mà các doanh nghiệp SMEs có thể triển khai để ứng dụng AI vào làm sạch dữ liệu, tối ưu hoá toàn bộ hệ thống dữ liệu vận hành.
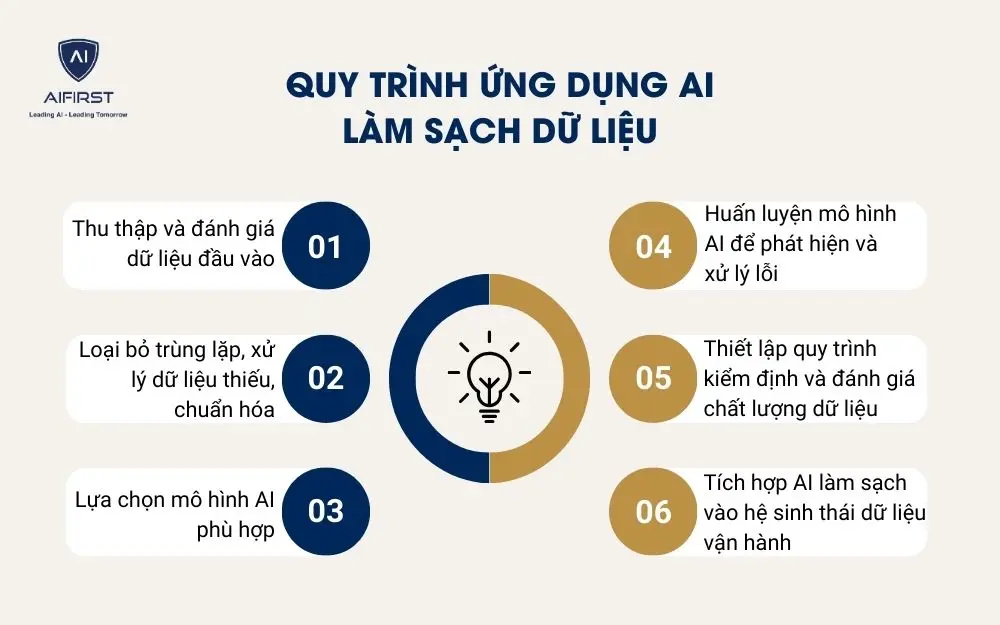
Bước 1: Thu thập và đánh giá dữ liệu đầu vào
Đây là bước khởi đầu quan trọng giúp doanh nghiệp hiểu rõ hiện trạng chất lượng dữ liệu đang có. Không thể làm sạch hiệu quả nếu không biết dữ liệu của mình đang ở tình trạng nào, thiếu gì, sai ở đâu và đến từ nguồn nào.
- Xác định các nguồn dữ liệu chính: CRM, POS, website, chatbot, form đăng ký, email marketing,...
- Phân loại dữ liệu theo mục đích sử dụng: Dữ liệu khách hàng, dữ liệu giao dịch, dữ liệu hành vi,...
- Đánh giá mức độ đầy đủ, trùng lặp, sai định dạng: Sử dụng công cụ BI, dashboard hoặc công cụ phân tích sơ bộ để phát hiện lỗi thường gặp.
- Gắn nhãn dữ liệu theo mức độ rủi ro hoặc mức độ ưu tiên xử lý: Ưu tiên các dữ liệu liên quan đến khách hàng, tài chính, chăm sóc sau bán.
Bước 2: Loại bỏ trùng lặp, xử lý dữ liệu thiếu, chuẩn hóa
Sau khi đánh giá hiện trạng, bước tiếp theo là làm sạch dữ liệu bằng cách áp dụng thuật toán AI và kỹ thuật xử lý dữ liệu để loại bỏ lỗi cơ bản. Đây là khâu giúp cải thiện tính chính xác và tính nhất quán trong toàn hệ thống.

- Sử dụng thuật toán AI để phát hiện dữ liệu trùng lặp: So sánh theo tên, email, số điện thoại, địa chỉ hoặc hành vi tương tự.
- Điền dữ liệu bị thiếu bằng mô hình gợi ý: Ví dụ: tự động điền giới tính dựa vào họ tên, địa phương dựa vào mã vùng điện thoại,...
- Chuẩn hóa định dạng: Ngày tháng theo một định dạng duy nhất, tên tỉnh/thành phố đồng nhất, định dạng email hợp lệ,...
- Loại bỏ dữ liệu lỗi nặng không thể phục hồi: Những bản ghi sai hoàn toàn hoặc trống hoàn toàn có thể bị xoá tự động theo tiêu chí AI đưa ra.
Bước 3: Lựa chọn mô hình AI phù hợp
Không phải mô hình AI nào cũng phù hợp cho mọi doanh nghiệp. Việc lựa chọn đúng thuật toán hoặc công nghệ xử lý dữ liệu sẽ giúp tiết kiệm tài nguyên, đạt hiệu suất tối ưu và dễ tích hợp với hệ thống hiện có.
- Xác định nhu cầu cụ thể: Doanh nghiệp cần phát hiện lỗi chính tả, phát hiện bản ghi trùng, dự đoán dữ liệu thiếu, hay phân loại dữ liệu?
- Chọn mô hình AI/ML phù hợp: Một số mô hình phổ biến bao gồm: Decision Tree, Clustering (phân cụm), NLP (xử lý ngôn ngữ tự nhiên), Deep Learning,...
- Tận dụng nền tảng có sẵn: Có thể sử dụng AI của Google Cloud, Amazon AWS, Azure hoặc công cụ tích hợp sẵn như Talend, DataRobot, MonkeyLearn,...
Bước 4: Huấn luyện mô hình AI để phát hiện và xử lý lỗi
Một trong những lợi thế lớn nhất của AI là khả năng tự học. Khi mô hình được huấn luyện trên dữ liệu thật, nó sẽ ngày càng chính xác hơn trong việc phát hiện lỗi và xử lý dữ liệu thông minh.
- Cung cấp tập dữ liệu huấn luyện (training dataset): Bao gồm dữ liệu sạch đã được chuẩn hóa và dữ liệu lỗi để mô hình học cách phân biệt.
- Sử dụng kỹ thuật supervised learning hoặc unsupervised learning: Tùy theo mục tiêu làm sạch (ví dụ: phân loại lỗi hay gợi ý sửa lỗi).
- Đánh giá độ chính xác và tinh chỉnh: Dựa trên các chỉ số như precision, recall, F1-score để cải thiện độ chính xác của mô hình.
- Lặp lại quy trình học - sửa - học: Cho phép AI cải thiện liên tục trong từng chu kỳ dữ liệu.
Bước 5: Thiết lập quy trình kiểm định và đánh giá chất lượng dữ liệu
Dữ liệu sau khi được làm sạch bởi AI cần được kiểm định lại để đảm bảo chất lượng trước khi đưa vào sử dụng. Bước này giúp doanh nghiệp kiểm soát rủi ro và tạo cơ chế giám sát liên tục.

- Xây dựng bộ tiêu chí đánh giá dữ liệu chuẩn: Xây dựng theo 7 tiêu chí: Chính xác, chuẩn xác, đầy đủ, nhất quán, đồng nhất, minh bạch, kịp thời.
- Tạo báo cáo tự động đánh giá chất lượng dữ liệu định kỳ: Báo cáo giúp nhận biết vấn đề ngay khi dữ liệu phát sinh lỗi mới.
- Giao KPI dữ liệu cho các bộ phận liên quan: Marketing, bán hàng, chăm sóc khách hàng cần có trách nhiệm duy trì chất lượng dữ liệu.
- Thiết lập vòng phản hồi giữa AI và người dùng: Người dùng có thể xác nhận hoặc chỉnh sửa nếu AI xử lý sai, từ đó mô hình học tốt hơn.
Bước 6: Tích hợp AI làm sạch vào hệ sinh thái dữ liệu vận hành
Sau khi mô hình AI đã hoạt động ổn định, doanh nghiệp cần đưa AI làm sạch vào vận hành thường xuyên như một phần không thể thiếu trong toàn bộ hệ sinh thái dữ liệu. Điều này giúp đảm bảo dữ liệu luôn sạch, mới và có thể sử dụng ngay.
- Tích hợp AI vào quy trình nhập liệu: Mọi dữ liệu mới từ chatbot, website, telesale,... sẽ được AI kiểm tra và chuẩn hóa ngay tại thời điểm thu thập.
- Kết nối AI với hệ thống CRM, CDP, DWH: Đảm bảo dữ liệu luân chuyển giữa các hệ thống đều đi qua lớp “lọc sạch” của AI.
- Tự động hóa toàn bộ chu trình làm sạch dữ liệu: Thiết lập lịch trình làm sạch hàng ngày, hàng tuần để duy trì dữ liệu chất lượng cao liên tục.
- Gắn AI vào dashboard theo dõi chất lượng dữ liệu: Giúp lãnh đạo giám sát tình trạng dữ liệu theo thời gian thực.
7. Thách thức khi làm sạch dữ liệu
Mặc dù việc làm sạch dữ liệu là yếu tố cốt lõi giúp doanh nghiệp vận hành hiệu quả, triển khai AI chính xác và tối ưu các hoạt động marketing nhưng trên thực tế, rất nhiều doanh nghiệp SMEs gặp khó khăn trong việc triển khai quy trình làm sạch dữ liệu một cách bài bản, liên tục và toàn diện. Dưới đây là những thách thức phổ biến nhất khi doanh nghiệp bắt tay vào quy trình làm sạch dữ liệu.
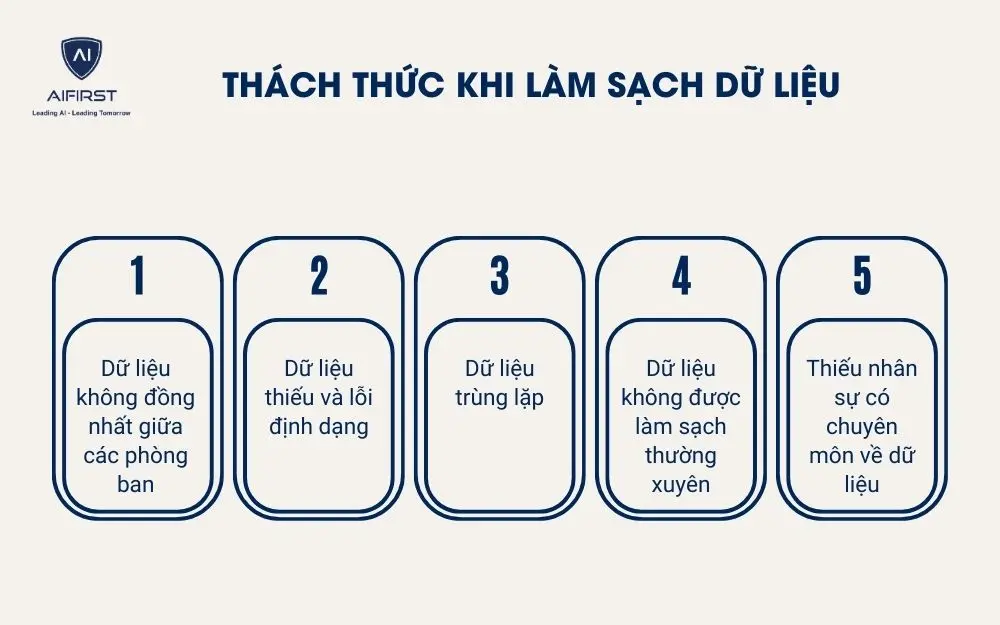
- Dữ liệu không đồng nhất giữa các phòng ban: Mỗi phòng ban lưu trữ dữ liệu theo cách riêng, định dạng riêng, tiêu chuẩn riêng. Bộ phận Marketing lưu tên khách hàng kiểu viết tắt, Sales dùng tên đầy đủ, CSKH ghi chú không chuẩn hoá,… dẫn đến khó kết nối và phân tích dữ liệu tổng thể. Sự không đồng nhất này khiến AI hoặc hệ thống phân tích không thể hoạt động hiệu quả.
- Dữ liệu thiếu và lỗi định dạng: Doanh nghiệp thường gặp tình trạng dữ liệu khách hàng bị thiếu thông tin (thiếu email, thiếu số điện thoại, không có địa chỉ…), hoặc định dạng không thống nhất (ngày tháng lộn xộn, số điện thoại sai ký tự,…). Điều này gây khó khăn lớn cho việc phân tích hành vi khách hàng và triển khai các chiến dịch marketing automation.
- Dữ liệu trùng lặp: Khi một khách hàng được ghi nhận nhiều lần với các thông tin khác nhau (đăng ký qua nhiều kênh, nhiều nhân viên nhập liệu), hệ thống sẽ không xác định được đâu là dữ liệu chính xác. Kết quả là báo cáo bị sai lệch, chăm sóc bị trùng lặp, và chi phí marketing bị đội lên vì gửi nhiều nội dung tới cùng một người.
- Dữ liệu không được làm sạch thường xuyên: Nhiều doanh nghiệp chỉ làm sạch dữ liệu một lần khi triển khai hệ thống mới, sau đó không duy trì quy trình kiểm tra định kỳ. Khiến dữ liệu nhanh chóng trở nên lỗi thời, sai lệch và không còn phù hợp cho việc ra quyết định hoặc triển khai AI về sau.
- Thiếu nhân sự có chuyên môn về dữ liệu: SMEs thường không có đội ngũ chuyên xử lý dữ liệu. Nhân viên marketing, sales hay admin thường kiêm nhiệm, không có kỹ năng xử lý dữ liệu chuyên sâu hoặc hiểu về chuẩn hóa dẫn đến làm sai quy trình, mất thời gian hoặc làm sai lệch thêm dữ liệu.
Làm sạch dữ liệu không chỉ là một bước kỹ thuật, mà là một chiến lược quan trọng giúp doanh nghiệp đảm bảo chất lượng thông tin từ đó tối ưu marketing, tăng hiệu quả bán hàng và vận hành trơn tru các hệ thống AI, CRM, CDP, automation,... Đặc biệt với các doanh nghiệp SMEs đang chuyển đổi sang mô hình kinh doanh online, việc ứng dụng AI vào làm sạch dữ liệu sẽ giúp tiết kiệm nguồn lực, giảm sai sót và duy trì lợi thế cạnh tranh lâu dài. Qua bài viết trên, AI First mong rằng sẽ giúp doanh nghiệp có thể ứng dụng AI vào làm sạch dữ liệu hiệu quả hơn từ đó gia tăng lợi nhuận, đem đến nhiều lợi ích cho doanh nghiệp.





